Téléchargé 1 051 fois






![2.4. Arrêt et démarrage d'une instance
sqlplus /nolog
sqlplus> connect sys/motdepasse as sysdba
sqlplus> startup nomount pfile=initora8i.ora
On obtient :
ORACLE instance started ORACLE instance started.
Total System Global Area
Fixed Size
Variable Size
Database Buffers
Redo Buffers
Database mounted.
56463824
86480
22642688
33554432
180224
bytes
bytes
bytes
bytes
bytes
La deuxième étape consiste à ouvrir les fichiers de contrôle :
sqlplus> alter database mount;
La troisième et dernière étape ouvre les fichiers redo et les fichiers de données :
sqlplus> alter database open;
Il est évidemment possible de réaliser toutes ces étapes en une seule commande :
sqlplus> startup open pfile=initora8i.ora
STARTUP
•
•
•
•
•
•
FORCE : permet de la fermer si elle ouverte puis de l'ouvrir
RESTRICT : filtrer les utilisateurs ayant accès à la base de données
OPEN : mode par défaut
RECOVER : permet de lancer un recouvrement avant ouverture
MOUNT : démarrage de l'instance et montage de la base de données
NOMOUNT : uniquement démarrage de l'instance
SHUTDOWN
•
•
•
•
[FORCE] [RESTRICT]
[PFILE = fichier d'initialisation]
{[OPEN][RECOVER]/[MOUNT][NOMOUNT]};
[ABORT/IMMEDIATE/NORMAL/TRANSACTIONAL];
ABORT : arrêt brutal, sans enregistrement préalable des données contenues dans la SGA, un
recouvrement sera nécessaire au redémarrage.
IMMEDIATE : refus de nouvelles connexion, annulation des transactions en cours, déconnexion des
utilisateurs, fermeture de la base de données dans un état cohérent, arrêt de l'instance.
NORMAL : mode par défaut : pas de nouvelles connexions et attente de la déconnexion des
utilisateurs.
TRANSACTIONAL : pas de nouvelles connexions, attente de la déconnexion des utilisateurs et
attente de fin de transaction avant l'arrêt.
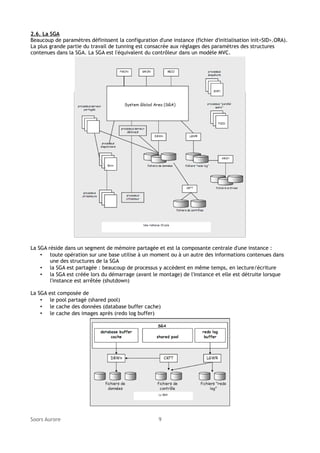
2.5. Le mode sysdba
Pour les opérations d'administration, il faut utiliser le mode SYSDBA ou SYSOPER. Par défaut, seul le
compte SYS peut obtenir une connexion de ce type là.
L'authentification SYSDBA peut être vérifiée de deux façons :
• par le système d'exploitation
• par le fichier de mot de passe
Soors Aurore
8](https://image.slidesharecdn.com/administration-131125075715-phpapp02/85/Administration-Base-de-donnees-Oracle-8-320.jpg)












![5.9.2. Lancer RMAN
Ligne de commande :
> RMAN target /
> RMAN target sys/aletest@aletest.world
Options :
• target => paramètre ORACLE_SID par défaut
• CATALOG
• CMDFILE => possibilité de batch
• LOG
• APPEND
Remarque : les options et commandes SQLPLUS sont utilisables (SET ECHO, SPOOL, etc).
5.9.3. Configurer RMAN
RMAN dispose de plusieurs réglages persistants utilisés par défaut.
Configurer la politique de conservation, rétention :
• fenêtre de restauration : nombre de jours dans le passé où on veut revenir
• fenêtre de redondance : indique combien de sauvegardes de chaque fichier doivent être
conservées (par défaut une)
RMAN > CONFIGURE RETENTION POLICY TO RECOVERY WINDOW OF n DAYS;
RMAN > CONFIGURE RETENTION POLICY TO REDUNDANCY n;
Configurer la sauvegarde automatique du fichier de contrôle :
• par défaut sauvegarde dans la zone de récupération rapide (flash recovery area )
• possibilité de destination par défaut spécifique
• active aussi la sauvegarde automatique du SPFILE
• sauvegarde automatique à chaque modification de structure de la base de données ou une
sauvegarde RMAN est enregistrée dans le fichier de contrôleur
RMAN > CONFIGURE CONTROLFILE AUTOBACKUP ON;
RMAN > CONFIGURE CONTROLFILE AUTOBACKUP
FORMAT FOR DEVICE TYPE DISK TO ‘<format>’;
L'utilisation de la zone de récupération rapide
• offre des fonctionnalités automatiques
• conseil d'utiliser un disque séparé pour cette zone
• sous répertoire avec différents types de fichiers (règles de nommage)
• une même zone peut être employée par plusieurs base de données à condition qu'elles aient un
nom unique
5.10. Sauvegarde
5.10.1. Généralités
Commande :
RMAN > BACKUP [comment] quoi [option]
Il faut que la base de données soit montée ou ouverte car il est nécessaire d'accéder au fichier de contrôle
de la base de donnée cible.
RMAN peut sauver des fichiers de données, de contrôle, de paramètres serveur, des éléments de
sauvegarde.
Une sauvegarde RMA peut être réalisée sous la forme d'une copie image ou d'un jeu de sauvegarde
(défaut). Dans un jeu de sauvegarde, il n'y a pas de sauvegarde des blocs jamais utilisés des bloc (et donc
gain de place) et compression possible.
Soors Aurore
25](https://image.slidesharecdn.com/administration-131125075715-phpapp02/85/Administration-Base-de-donnees-Oracle-25-320.jpg)
![Paramètres courants :
• comment?
◦ INCREMENTALE LEVEL n [CUMULATIVE]
◦ VALIDATE (simulation comme nero)
◦ AS COPY ou AS BACKUPSET
• quoi?
◦ DATABASE
◦ TABLESPACE cible
◦ DATAFILE cible
◦ CURRENT CONTROLFILE
◦ SPFILE
◦ ARCHIVELOG cible
• option:
◦ INCLUDE CURRENT CONTROL FILE
◦ PLUS ARCHIVELOG
◦ FORMAT='<format>'
◦ NOT BACKED UP clause_depuis
5.10.2. Manipulations
5.10.2.1. Sauvegarde de la totalité de la base de données
RMAN > BACKUP [VALIDATE] DATABASE;
5.10.2.2.
RMAN >
RMAN >
RMAN >
Sauvegarde de tablespaces ou fichiers de données
BACKUP TABLESPACE user, index;
BACKUP DATAFILE 1,2, ‘<rep/fichier>’;
BACKUP TABLESPACE system DATAFILE 5;
5.10.2.3.
RMAN >
RMAN >
RMAN >
RMAN >
Sauvegarde du fichier de contrôle et du spfile
BACKUP … INCLUDE CURRENT CONTROLFILE;
BACKUP CURRENT CONTROLFILE;
BACKUP AS COPY CURRENT CONTROLFILE;
BACKUP SPFILE;
5.10.2.4. Sauvegarde de fichier archivés
Si pas multiplexé et si pas archivés dans la zone de récupération rapide
RMAN > BACKUP ARCHIVELOG ALL;
RMAN > BACKUP ARCHIVELOG FROM TIME ‘SYSDATE-1’ DELETE ALL INPUT;
RMAN > BACKUP AS COMPRESSED BACKUPSET ARCHIVELOG FROM TIME
‘SYSDATE-7’ NOT BACKED UP 2 TIMES;
RMAN > BACKUP DATABASE PLUS ARCHIVELOG;
RMAN > BACKUP DATABASE PLUS ARCHIVELOG DELETE ALL INPUT;
Commande BACKUP ... PLUS ARCHIVELOG :
1. Archivage du fichier de journalisation courant
2. Sauvegarde de tous les fichiers de journalisation archivés
3. Sauvegarde des autres éléments
4. Archivage, à nouveau, du fichier de journalisation courant
5. Sauvegarde des fichiers de journalisation archivés générés depuis le début de la sauvegarde
Option NOT BACKED UP : pour ne pas sauvegarder que les fichiers de journalisation archivés qui n'ont pas
déjà été sauvegardés un nombre de fois ou depuis un certain temps
5.10.2.5. Sauvegarde incrémentale
Elle permet de sauvegarder uniquement les blocs qui ont été modifiés depuis la dernière sauvegarde. A
utiliser plutôt lorsque l'activité de mise à jour est relativement faible
RMAN > BACKUP INCREMENTAL LEVEL 0 DATABASE;
RMAN > BACKUP INCREMENTAL LEVEL 1 DATABASE;
Soors Aurore
26](https://image.slidesharecdn.com/administration-131125075715-phpapp02/85/Administration-Base-de-donnees-Oracle-26-320.jpg)


![5.11. Le repository RMAN
5.11.1. Trouver les informations
5.11.1.1. La Commande LIST
Elle permet d'afficher des informations sur les sauvegardes et les fichiers de journalisation archivés.
RMAN > LIST cible [BY FILE | SUMMARY] [filtre_sauvegarde];
RMAN > LIST {BACKUPSET | BACKUPPIEC}{liste_clés | tag=‘nom’};
RMAN > LIST ARCHIVELOG [ALL | filtre_archive][info_sauvegarde];
Exemples :
RMAN > LIST
RMAN > LIST
RMAN > LIST
RMAN > LIST
RMAN > LIST
RMAN > LIST
RMAN > LIST
RMAN > LIST
BACKUP
BACKUP
BACKUP
BACKUP
BACKUP
BACKUP
BACKUP
BACKUP
OF DATABASE;
OF DATAFILE 1;
OF TABLESPACE system, sysaux.
OF CONTROLFILE SPFILE;
OF ARCHIVELOG ALL
OF ARCHIVELOG UNTIL TIME ‘SYSDATE_1’;
TAG=‘DBINC0’;
COMPLETED AFTER ‘SYSDATE_1’;
RMAN > LIST BACKUPSET 8;
RMAN > LIST BACKUPSET TAB=‘DBINC0’;
RMAN > LIST BACKUPPIECE 76;
RMAN > LIST ARCHIVELOG ALL;
# dans la dernière heure
RMAN > LIST ARCHIVELOG FROM TIME ‘SYSDATE_1/24’;
# archives sauvegardées 2 fois sur disque
RMAN > LIST ARCHIVELOG ALL BACKED UP 2 TIMES TO DEVICE TYPE DISK;
# archives jamais sauvegardées sur disque
RMAN > LIST ARCHIVELOG ALL BACKED UP 0 TIMES;
5.11.1.2. La commande REPORT
• réaliser des interrogations plus évoluées
• utilisations principales :
1. lister les éléments qui nécessitent une sauvegarde
2. lister les sauvegardes obsolètes
3. afficher la liste des fichiers de données de la base de données
1. Lister les éléments qui nécessitent une sauvegarde :
RMAN > REPORT NEED BACKUP [condition][objets];
Options :
• Condition :
◦ DAYS = n
◦ incremental = n
◦ recovery window of n days
◦ redundancy = n
• Objets :
◦ database
◦ database <liste>
◦ tablespace <liste>
Soors Aurore
29](https://image.slidesharecdn.com/administration-131125075715-phpapp02/85/Administration-Base-de-donnees-Oracle-29-320.jpg)
![2. Lister les sauvegardes obsolètes
RMAN > REPORT OBSOLETE [condition];
Options :
• Conditions
◦ recovery window of n days
◦ redundancy = n
3. Afficher la liste des fichiers de données de la base de données
RMAN > REPORT SCHEMA;
5.11.2. Gérer le repository
5.11.2.1. La commande CROSSCHECK
• vérifier que les informations enregistrées dans le dictionnaire correspondent bien à des fichiers
existants
• trois status possibles : expired / available / unavailable
RMAN > CROSSCHECK cible [filtre_sauvegarde];
RMAN > CROSSCHECK {BACKUPSET | BACKUPPIECE}{liste_cles | tags};
RMAN > CROSSCHECK ARCHIVELOG [ALL | filtre_archive];
5.11.2.2. La commande DELETE
Elle permet de supprimer des sauvegardes (suppression physique + dans le repository).
Variantes possibles :
• supprimer des sauvegardes ou fichiers de journalisation
• supprimer les sauvegardes obsolètes.
5.11.2.3. La commande CATALOG
Elle permet d'indiquer à RMAN l'existence de fichiers de journalisation archivés ou d'éléments de
sauvegarde qui ne sont pas enregistrés dans le référentiel RMAN.
Cas possibles :
• mauvais emploi de DELETE, le fichier physique est toujours la
• récupération avec mauvais fichier de contrôle
• recréation de fichier de contrôle (il est vide)
• erreur sur le fichier de contrôle
• déplacement du fichier physique
5.12. Restauration
5.12.1. Vue d'ensemble
Plusieurs facteurs dépendants :
• nature du/des fichiers endommagé(s) ou perdu(s)
• mode de fonctionnement de la base (archivelog ou non)
• sauvegarde possible
Que faire :
• identifier la nature du problème
• définir le mode opératoire
Conseil inital : avant de commencer toute opération de restauration, réaliser une sauvegarde complète de
la base endommagée. Au minimum une sauvegarde du fichier de contrôle et des ficher de journalisation
en ligne.
Soors Aurore
30](https://image.slidesharecdn.com/administration-131125075715-phpapp02/85/Administration-Base-de-donnees-Oracle-30-320.jpg)

![5.12.4. Identification de la nature des problèmes
• message d'erreur concernant les fichiers de contrôle : ORA-00204 à ORA-00206
• message d'erreur concernant les fichiers de journalisation : ORA-00312 à ORA-00321
• message d'erreur concernant les fichiers de données : ORA-01157 à ORA-01110
Lorsque la base de données montée ou ouverte, on peut interroger la vue V$RECOVER_FILE pour
déterminer la liste des fichiers de données sur lesquels il existe un problème.
5.12.5. Les commandes RMAN
L'objectif principal est de bien choisir la cible en fonction de la nature du problème. Ensuite RMAN se
charge de tout :
• identifier les sauvegardes à utiliser;
• en extraire les fichiers requis;
• identifier les fichiers de journalisation archivés nécessaires
• les extraire d'une sauvegarde s'ils ont été sauvegardés puis supprimés
5.12.5.1. La commande RESTORE
RMAN > RESTORE cible [options]
Options :
• PREVIEW : lister les sauvegardes dont RMAN a besoin pour réaliser la restauration correspondante
• VALIDATE : tester si la restauration peut être restaurée
5.12.5.2. La commande RECOVER
RMAN > RECOVER cible [options]
Lors de l'opération de récupération, RMAN recherche les fichiers de journalisation archivés dont il a besoin
en premier lieu sur le disque. Les fichiers de journalisation archivés manquant sont automatiquement
restaurés à partir de sauvegardes, vers le répertoire d'archivage défini par le paramètre
LOG_ARCHIVE_DEST_1
5.12.6. Scénarios de restauration
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
Restauration du SPFILE
Restauration d'un fichier de contrôle
Restauration d'un fichier de journalisation
Restauration complète de la totalité d'une base de données en mode ARCHIVELOG
Restauration complète d'une partie d'une base de données en mode ARCHIVELOG
Restauration de tous les fichiers de contrôle en mode ARCHIVELOG
Restauration incomplète en mode ARCHIVELOG
Restauration en mode NOARCHIVELOG
Restauration à un emplacement différent
Tablespace temporaire géré localement
Hypothèses de départ :
• la sauvegarde automatique du fichier de contrôle et du SPFILE est activée
• utilisation d'une zone de récupération rapide
• pas de base de données annexe pour stocker le repository RMAN
Remarque : si le fichier SPFILE, ou de contrôle, ou de journalisation est perdu, d'abord résoudre ces
problèmes avant de traiter le cas des fichiers de données.
Soors Aurore
32](https://image.slidesharecdn.com/administration-131125075715-phpapp02/85/Administration-Base-de-donnees-Oracle-32-320.jpg)



![5.12.6.7. Scénario 7 : Restauration incomplète en mode ARCHIVELOG
Hypothèse : tout est perdu : fichier SPFILE, fichier de contrôle, fichier de données, fichier de
journalisation en ligne.
Ce type de restauration est nécessaire dans les cas suivants :
• perte de tous les redo log file
• perte d'un fichier de journalisation archivé nécessaire à une récupération
• retour avant un ordre SQL malencontreux (drop table, etc)
Dans tous les cas, il faut identifier le point de retour (SCN, timestamp, sequence) souhaité.
Mode opératoire :
1. Positionner le SID
2. Démarrer l'instance sans la monter
3. Restaurer le fichier de paramètres serveur
4. Redémarrer l'instance sans la monter (démarrage avec le SPFILE)
5. Restaurer les fichiers de contrôle
6. Monter la base
7. Synchroniser le référentiel RMAN avec le contenu de la zone
Exemple :
RMAN > SET DBID <numero>
RMAN > STARTUP NOMOUNT
RMAN > RESTORE SPFILE FROM ‘<rep+nom fichier>’;
RMAN > STARTUP NOMOUNT FORCE;
RMAN > RESTORE CONTROLFILE FROM AUTOBACKUP;
RMAN > SQL « ALTER DATABASE MOUNT »;
RMAN > CATALOG RECOVERY AREA NOPROMPT ;
RMAN > CATALOG START WITH ‘rep’ NOPROMPT;
RMAN > SQL « ALTER DATABASE OPEN RESETLOGS »;
5.12.6.8. Scénario 8 : Restauration en mode NOARCHIVELOG
Hypothèses :
• perte de tout ou une partie de la base de données
• mode noarchivelog
Solution : ramener la base de donnée à l'état où elle se trouvait lors de la dernière sauvegarde complète
base fermée. Si les fichiers de journalisation sont disponibles et qu'il n'y a pas eu un cycle complet de
basculement des fichiers de journalisation depuis la dernière sauvegarde, on peut alors tenter une
restauration de type archivelog. Si la récupération signale une erreur, la situation est à priori désespérée.
Dans ce cas, on peut « tenter » une restauration en mode NOARCHIVELOG.
Mode opératoire :
1. Positionner le SID
2. Démarrer l'instance sans la monter
3. Restaurer les fichiers de contrôle à partir d'une sauvegarde automatique
4. Monter la base
5. Restaurer la base
6. (éventuellement) restauration incrémentale
7. Ouvrir la base de données avec option RESETLOGS
Exemple :
RMAN > SET DBID <numero>
RMAN > STARTUP NOMOUNT
RMAN > RESTORE CONTROLFILE FROM AUTOBACKUP;
RMAN > SQL « ALTER DATABASE MOUNT »;
RMAN > RESTORE DATABASE ;
RMAN > RECOVER DATABASE NOREDO;]
RMAN > SQL « ALTER DATABASE OPEN RESETLOGS »;
Soors Aurore
36](https://image.slidesharecdn.com/administration-131125075715-phpapp02/85/Administration-Base-de-donnees-Oracle-36-320.jpg)


Le document fournit une vue détaillée de l'administration d'une base de données Oracle, abordant des aspects tels que l'architecture, la structure logique et physique, ainsi que la gestion des instances et des processus. Il couvre également les utilisateurs, les privilèges, et les stratégies de sauvegarde et de récupération, tout en décrivant les composants tels que les tablespaces, segments et blocs. Les procédures pour le démarrage, l'arrêt et la restauration des bases de données sont aussi expliquées, avec un accent sur l'importance de la cohérence et de la sécurité des données.



































































![Cours_de_Base [Enregistrement automatique].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/coursdebaseenregistrementautomatique-251004134501-ee1a28b9-thumbnail.jpg?width=640&height=640&fit=bounds)












