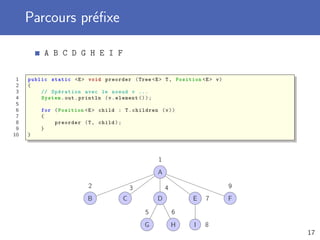
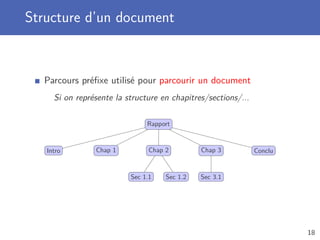
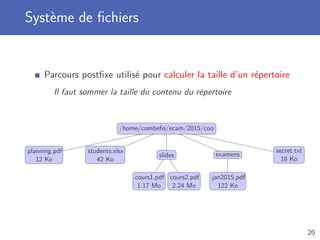
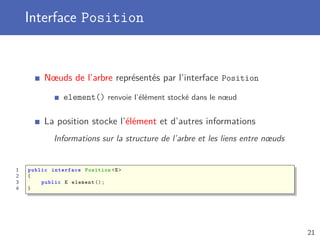
Télécharger en tant que PDF, PPTX






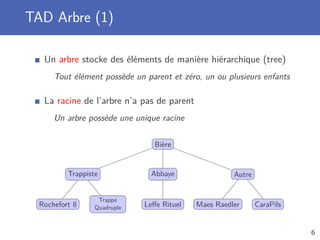


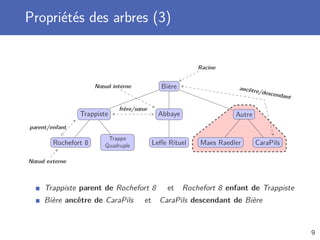















![Recherche linéaire
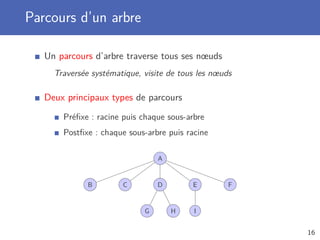
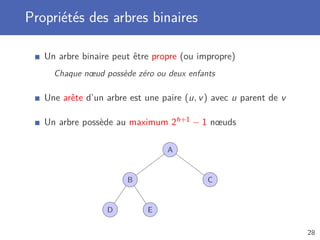
Parcours de la structure de donnée, élément par élément
Jusqu’à trouver l’élément ou avoir parcouru toute la structure
Complexité temporelle en O(n)
Dans le pire des cas, tous les élément sont parcourus
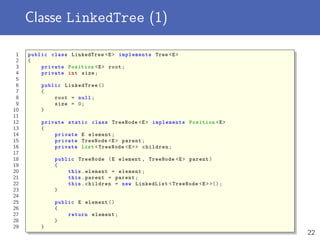
1 public static boolean find (int [] data , int elem)
2 {
3 for (int i = 0; i < data.length; i++)
4 {
5 if (data[i] == elem)
6 {
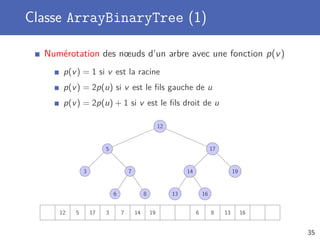
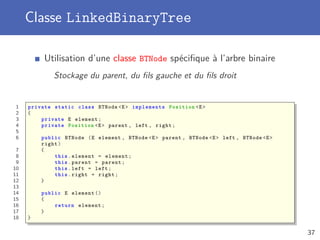
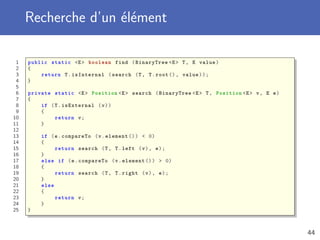
7 return true;
8 }
9 }
10 return false;
11 }
41](https://image.slidesharecdn.com/ecam-coo3be-2015-cours7-slides-151114152626-lva1-app6892/85/Arbre-et-algorithme-de-recherche-41-320.jpg)







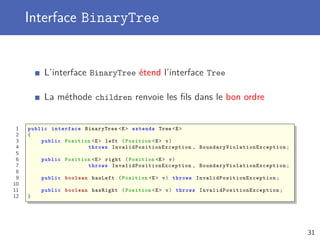
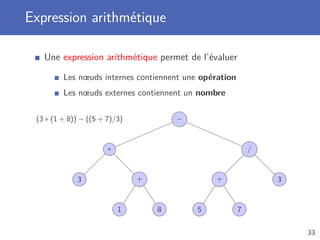
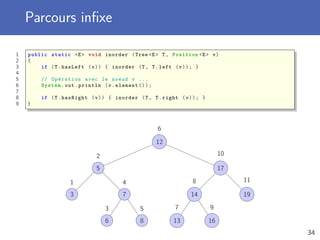
Le document traite de la programmation orientée objet avec un accent particulier sur les arbres et les algorithmes de recherche. Il présente les concepts de structures de données, les différentes propriétés des arbres, leurs implémentations, ainsi que les algorithmes de parcours et de recherche. Des exemples de méthodes spécifiques pour manipuler des arbres binaires et leur utilisation dans divers contextes sont également fournis.

















































































