Télécharger en tant que PDF, PPTX




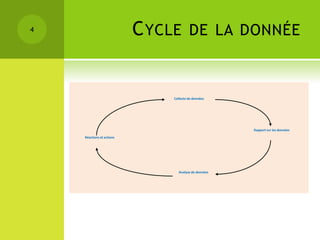


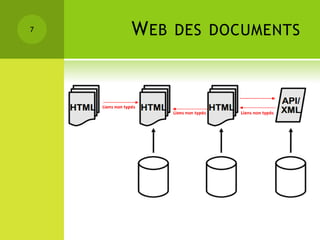

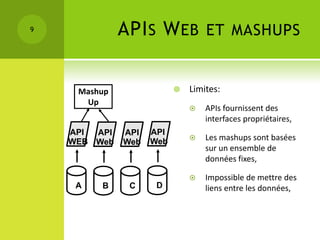
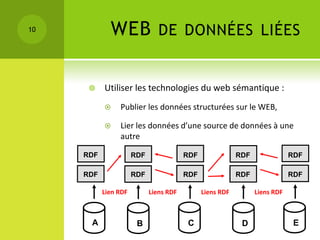




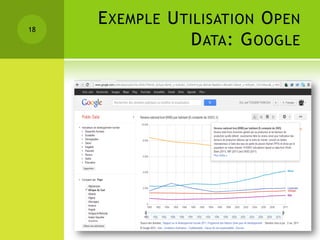





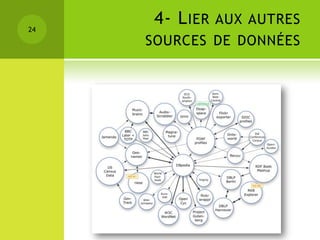

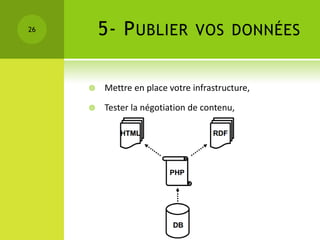



Le colloque sur la gestion des données épidémiologiques a abordé les enjeux de la collecte et de la publication des données, mettant l'accent sur l'open data comme moyen de rendre ces informations accessibles et exploitables. Les participants ont discuté des principes liés aux données liées et aux technologies du web sémantique pour améliorer l'interconnexion et l'analyse des données. Les étapes pour publier des données ouvertes comprennent la compréhension des principes, l'identification des données clés, le choix des URIs, l'établissement de liens avec d'autres sources et la mise en place de l'infrastructure de publication.









































































