Téléchargé 33 fois


![In 2011, the amount of information created and replicated
will surpass 1.8 zettabytes (1.8 trillion gigabytes) -
growing by a factor of 9 in just five years. […] and more
than doubling every two years. That's nearly as many bits
of information in the digital universe as stars in our
physical universe.
John Gantz and David Reinsel
Extracting Value from Chaos](https://image.slidesharecdn.com/bigdatabuzzouopportunit-130410100746-phpapp02/85/Big-Data-buzz-ou-opportunite-3-320.jpg)
![Explosion généralisée des
données
―[by 2020] data use is ―Flickr members ―AT&T has about 19 ―We now have well
expected to grow by upload more than petabytes of data over a thousand
as much as 44 3,000 images every transferred through customers in the ever-
minute, and yesterday their networks each growing EMC
times, amounting to
yeoaaron uploaded day.‖ Petabyte Club.
some 35.2ZB the five billionth They—or frequently
(zettabytes—a billion photo…‖ many more—
terabytes) globally.‖ petabytes of EMC
storage in production.
By 2012 or so, we're
forecasting that we'll
have to start a
new, informal club—
the EMC Exabyte
Club.‖](https://image.slidesharecdn.com/bigdatabuzzouopportunit-130410100746-phpapp02/85/Big-Data-buzz-ou-opportunite-4-320.jpg)



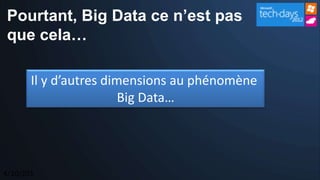

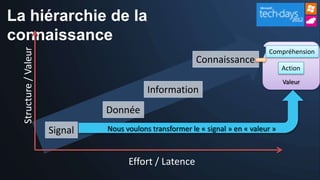


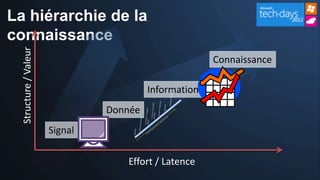
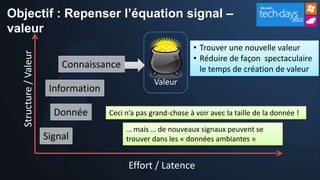

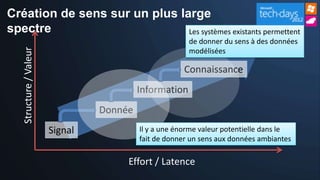


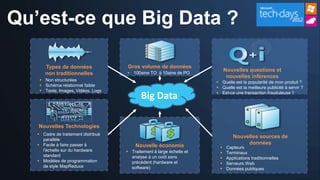

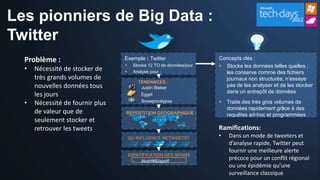





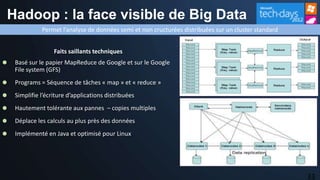








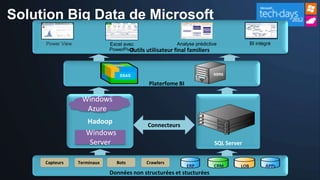




Le document présente les opportunités et défis du 'Big Data' pour les entreprises, mettant en lumière l'explosion des données et leur valeur potentielle pour la prise de décision. Il aborde les technologies qui facilitent l'analyse rapide et la création de sens à partir de données non structurées, ainsi que l'importance de la hiérarchie de la connaissance pour extraire de la valeur des signaux. La stratégie de Microsoft pour intégrer ces technologies dans ses produits est également discutée, avec un accent sur l'accessibilité et l'optimisation des outils d'analyse de données.








































































