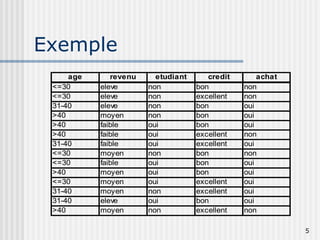
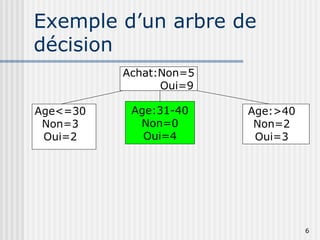
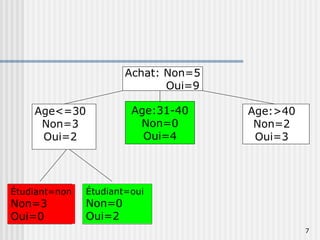
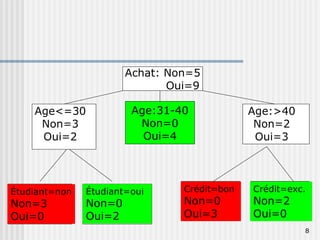
Les arbres de décision sont des outils utilisés pour prédire une variable cible à partir de plusieurs variables explicatives en divisant les données en sous-groupes. Ils permettent de générer des règles simples pour la segmentation de la population et l'identification des variables discriminantes. Des algorithmes comme CHAID et CART sont couramment utilisés pour construire ces arbres, avec des conditions spécifiques pour leur croissance et leur élagage.