Télécharger en tant que PDF, PPTX




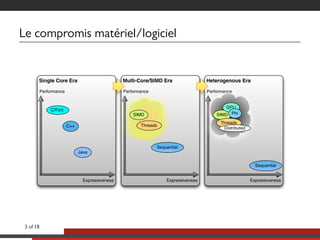
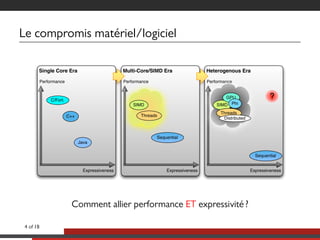





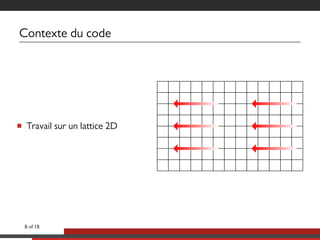


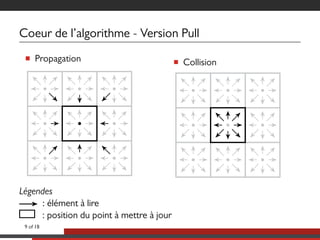

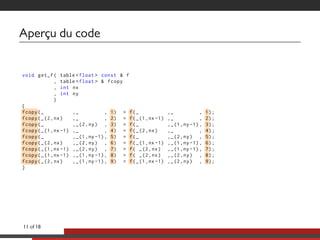
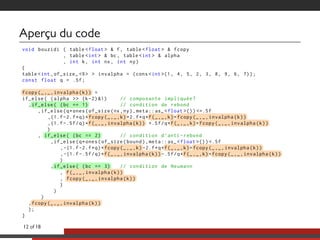


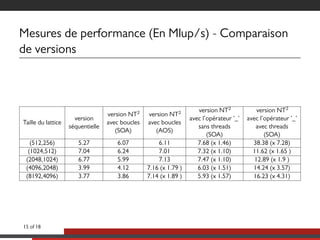
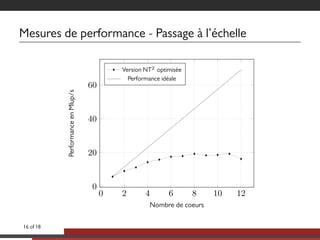


Le document présente une approche multicoeurs pour l'algorithme Lattice Boltzmann en utilisant la bibliothèque NT2, qui offre une interface semblable à MATLAB pour le calcul scientifique. Il souligne les compromis entre performance et expressivité à travers diverses architectures de traitement, en se concentrant sur le parallélisme et l'efficacité. Des mesures de performance sont fournies pour différentes versions de l'algorithme, montrant les améliorations significatives possibles avec des optimisations adaptées.














































