Télécharger en tant que PDF, PPTX






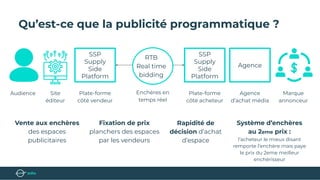
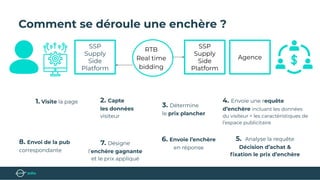




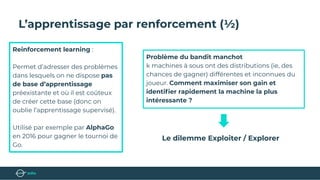

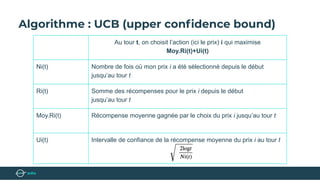
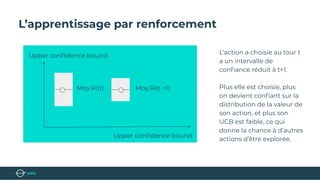
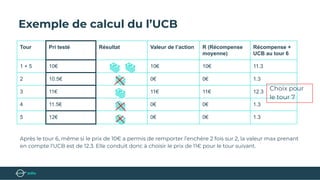






Le document présente un bootcamp de science des données axé sur l'optimisation des publicités grâce au machine learning. Il explique le fonctionnement de la publicité programmatique et l'utilisation de l'apprentissage par renforcement pour maximiser les revenus publicitaires en temps réel. Des stratégies algorithmiques, comme le critère de l'Upper Confidence Bound (UCB), sont abordées pour équilibrer l'exploration et l'exploitation des choix de prix.















































