Télécharger pour lire hors ligne
































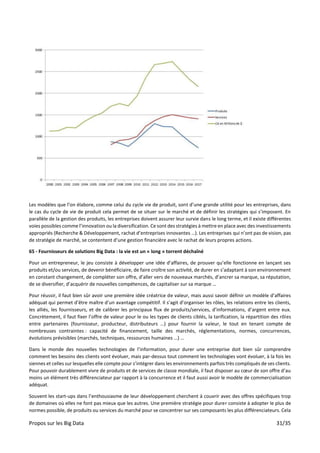

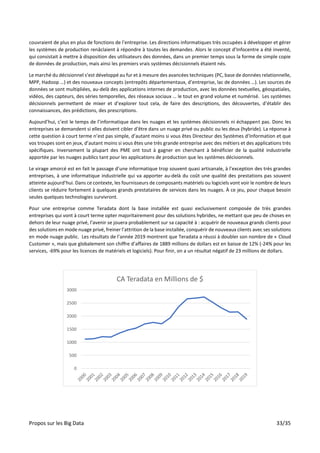



Le document aborde les implications des big data sur l'analyse, l'intelligence artificielle et la société, en soulignant l'importance des compétences nécessaires pour en tirer parti. Il présente des défis et des opportunités liés à la compréhension, à l'analyse et à la mise en œuvre de solutions fondées sur les big data, tout en reconnaissant la nécessité de méthodes qualitatives et quantitatives. Enfin, il souligne que la gestion des big data doit être ouverte à des réflexions sur l'éthique et la protection de la vie privée.















































