Téléchargé 254 fois

![Références
• [1] Robinson I., Webber J, Eifrem E., “Graph Databases”, O’Reilly, 2nd edition, ISBN
9781491930892
• [2] Vukotic A., Watt N., “Neo4j in Action”, Manning Publications, ISBN 9781617290763
• [3] Wikipedia, “Base de données orientée graphe”,
https://fr.wikipedia.org/wiki/Base_de_donn%C3%A9es_orient%C3%A9e_graphe
• [4] Willemsen C., “Découverte de Neo4j, la base de données graphe”,
http://neoxygen.io/articles/decouverte-de-neo4j.html , version 1.1, 14-01-2015
• [5] Maury F., “Pourquoi s’intéresser aux graph-databases ?”,
http://www.arolla.fr/blog/2013/10/pourquoi-sinteresser-aux-graph-databases/
• [6] Fauvet C., “Nouvelles opportunités pour les données fortement connectées: La base de
graphe Neo4j”, 10 décembre 2013
• [7] Robert M., Dutheil L., Domenjoud M., « Introduction aux graphes avec Neo4j et Gephi »
http://blog.octo.com/introduction-aux-graphes-avec-neo4j-et-gephi/
• [8] Lyon William, Introduction to Graph Databases and Neo4j - January 14, 2016,
https://www.youtube.com/watch?v=83P81ebgCxA
19 janvier 2016 3](https://image.slidesharecdn.com/prsentationbdgraphes-draft6-160120072438/85/Base-de-donnees-graphe-et-Neo4j-3-320.jpg)





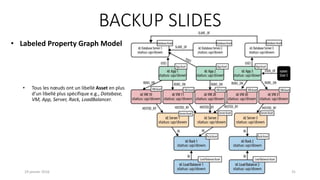
![Labeled Property Graph Model
19 janvier 2016 13
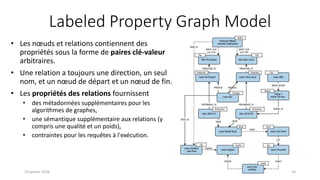
• Les « property graphs » sont un type de
graphe particulier dans lequel à la fois les
nœuds et les relations peuvent avoir des
propriétés, ce qui offre donc un modèle de
données entièrement dynamique [7].
• Composés par
• des nœuds
• des relations
• des propriétés
• des libellés](https://image.slidesharecdn.com/prsentationbdgraphes-draft6-160120072438/85/Base-de-donnees-graphe-et-Neo4j-13-320.jpg)












Le document présente les bases de données graphe, en mettant l'accent sur leur modèle de données et leurs avantages par rapport aux bases relationnelles et aux autres bases NoSQL. Il discute de l'architecture de Neo4j, un leader dans ce domaine, ainsi que de cas d'usage concrets et des aspects techniques tels que le stockage, le traitement et la résilience. Enfin, le document aborde des concepts clés comme le modèle de graphe étiqueté et la scalabilité.









































































