Le chapitre traite des variables aléatoires discrètes, définies comme des fonctions associant des résultats d'épreuves aléatoires à des nombres réels. Il explique comment définir la loi de probabilité d'une variable aléatoire discrète et présente la fonction de répartition, qui indique la probabilité cumulée. Enfin, il aborde des propriétés telles que l'espérance mathématique, qui est la moyenne pondérée des valeurs possibles, et comment elle est affectée par des changements d'origine ou d'échelle.


![2 Loi de probabilité d’une variable aléatoire discrète
Soit X une variable aléatoire discrète dont l’ensemble des valeurs possibles est donné par X (Ω) = {x1, x2, . . . xi, . . . , xk} .
Associer à chacune des valeurs possibles de X la probabilité qui lui correspond, c’est définir la loi de probabilité
(ou distribution de probabilité) de la variable aléatoire X.
A toute valeur possible xi de la variable aléatoire X, on fait correspondre un nombre Pi, compris entre 0 et 1,
défini par :
Pi = P(X = xi), i : 1 . . . k
avec Pi ≥ 0 et
kP
i=1
Pi = 1
2.1 Définition
La loi de probabilité d’une variable aléatoire discrète est définie par l’ensemble des couples (xi, Pi) :
X : x1 x2 . . . xi . . . xk
Pi = P(X = xi) : P1 P2 . . . Pi . . . Pk
Parfois cette liste de valeurs caractérisant un tableau de distribution d’une variable aléatoire peut être résumée
par une formule mathématique. Si c’est le cas, la loi de probabilité sera définie par une fonction :
f : X (Ω) −→ [0, 1]
x 7−→ f (x) = P(X = x)
Suite de l’exemple 2 :
Reprenons l’exemple qui consiste à jeter 2 fois une pièce de monnaie. La variable aléatoire X est définie par "le
nombre de piles obtenus". X peut prendre les valeurs 0,1 et 2 (X (Ω) = {0, 1, 2})
Pour déterminer la loi de probabilité de la variable aléatoire X, il suffit d’associer, à chacune des valeurs possibles
de X, la probabilité correspondante :
P1 = P(X = 0) = P ({(F, F)}) =
1
4
P2 = P(X = 1) = P ({(P, F) , (F, P)}) =
1
2
P3 = P(X = 2) = P ({(P, P)}) =
1
4
La loi de probabilité de X est donnée par
X : 0 1 2
Pi = P(X = xi) :
1
4
1
2
1
4
avec
P
x∈X(Ω)
P(X = x) = 1
2.2 Représentation graphique de la distribution d’une variable aléatoire discrète
La représentation graphique de la loi de probabilité dans le cas discret se fait à l’aide d’un diagramme en bâtons
3 Fonction de répartition
3.1 Définition
Soit X une variable aléatoire discrète, la fonction de répartition, notée F, de la v.a X est une fonction positive non
décroissante, définie par :
F : R −→ [0, 1]
x 7−→ F (x) = P (X < x) =
P
xi<x
P (X = xi)
F (x) = P (X < x) : indique la probabilité que la v.a X prenne une valeur strictement inférieure à x.
2](https://image.slidesharecdn.com/cours-stat2-kharrat-161102173803/85/Cours-stat2-kharrat-2-320.jpg)
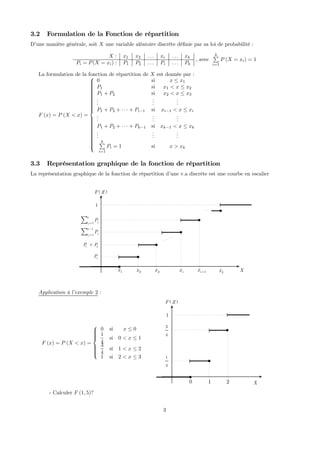

![F (x) =
⎧
⎪⎪⎪⎪⎪⎪⎪⎪⎨
⎪⎪⎪⎪⎪⎪⎪⎪⎩
0 si x ≤ 1
1
4
si 1 < x ≤ 2
1
3
si 2 < x ≤ 3
2
3
si 3 < x ≤ 4
1 si x > 4
- Déterminer la loi de probabilité de X?
Il faut tout d’abord remarquer que la variable aléatoire en question est une variable aléatoire discrète puisque
sa fonction de répartition est discontinue et constante par intervalle.
F (x) prend la valeur 0, ∀x ≤ x1 = 1, en particulier F (x1) = 0.
Pour x ∈ ]x1 = 1, x2 = 2], on a F (x) =
1
4
, en particulier F (x2) =
1
4
.
Pour x ∈ ]x2 = 2, x3 = 3], on a F (x) =
1
3
, en particulier F (x3) =
1
3
.
Pour x ∈ ]x3 = 3, x4 = 4], on a F (x) =
2
3
, en particulier F (x4) =
2
3
.
∀x ≥ x4, F (x) prend la valeur 1.
Ainsi, la variable aléatoire X peut prendre les valeurs x1 = 1, x2 = 2, x3 = 3 et x4 = 4 (X (Ω) = {1, 2, 3, 4}).
F (x2) − F (x1) = P (X = x1) = P1 =
1
4
; F (x3) − F (x2) = P (X = x2) = P2 =
1
12
F (x4) − F (x3) = P (X = x3) = P3 =
1
3
; et puisque
4P
i=1
Pi = 1, alors P4 = 1 −
µ
1
4
+
1
12
+
1
3
¶
=
1
3
La loi de probabilité de X est donc
X : 1 2 3 4
Pi :
1
4
1
12
1
3
1
3
4 Les paramètres descriptifs d’une variable aléatoire discrète
4.1 Espérance mathématique
L’espérance mathématique d’une v.a discrète est égale à la somme des valeurs possibles xi pondérées par leurs
probabilités Pi
E (X) =
kX
i=1
xiP (X = xi)
Si la variable n’est pas finie (c.-à-d. X (Ω) est un ensemble infini dénombrable), alors l’espérance mathématique
est donnée par :
E (X) =
∞X
i=1
xiP (X = xi)
Dans ce cas, E (X) n’existe que si la série
∞P
i=1
xiP (X = xi) est convergente (chapitre I -Math I)
N.B : Pour le reste du cours, on utilisera la notation suivante :E (X) =
P
x∈X(Ω)
xP (X = x)
4.1.1 Propriétés de l’espérance mathématique
a/ l’espérance mathématique d’une constante est égale à la constante elle même.
E (a) = a
b/ changement d’origine :
E (X + b) =
P
x∈X(Ω)
(x + b) P (X = x) =
P
x∈X(Ω)
xP (X = x) + b
P
x∈X(Ω)
P (X = x) = E (X) + b
E (X + b) = E (X) + b
5](https://image.slidesharecdn.com/cours-stat2-kharrat-161102173803/85/Cours-stat2-kharrat-5-320.jpg)
![c/ changement d’échelle :
E (aX) =
P
x∈X(Ω)
axP (X = x) = a
P
x∈X(Ω)
xP (X = x) = aE (X)
E (aX) = aE (X)
b/ et c/ =⇒ E (aX + b) = aE (X) + b
d/ La somme des écarts, pondérées par les probabilités, entre les valeurs xi et l’espérance mathématique E (X)
est nulle :
E (X − E (X)) =
P
x∈X(Ω)
(x − E (X)) P (X = x) =
P
x∈X(Ω)
xP (X = x) − E (X)
P
x∈X(Ω)
P (X = x)
= E (X) − E (X) = 0
E (X − E (X)) = 0
4.1.2 Espérance mathématique d’une fonction de X
Soit X une variable aléatoire discrète sur laquelle on applique une fonction numérique quelconque ψ.
X
Ω ( )X IRΩ ⊂
ψ
IR
Xψ
ψ (X) est aussi une variable aléatoire discrète.
Si elle existe, l’espérance mathématique de ψ (X) est :
E (ψ (X)) =
X
x∈X(Ω)
ψ (x) P (X = x) =
X
i
ψ (xi) P (X = xi)
Les moments non centrés : ψ (X) = Xk
Le moment non centré d’ordre k de X, noté mk est défini par :
mk = E
¡
Xk
¢
=
X
x∈X(Ω)
xk
P (X = x)
pour k = 0 m0 = E (1) = 1
pour k = 1 m1 = E (X) ⇒ l’espérance est le moment non centré d’ordre 1
pour k = 2 m2 = E
¡
X2
¢
=
P
x∈X(Ω)
x2
P (X = x)
Les moments centrés : ψ (X) = [X − E (X)]k
Le moment centré d’ordre k de X, noté µk est défini par :
µk = E [X − E (X)]
k
=
X
x∈X(Ω)
(x − E (X))
k
P (X = x)
pour k = 0 µ0 = E (1) = 1
pour k = 1 µ1 = E (X − E (X)) = 0
pour k = 2 µ2 = E (X − E (X))2
= E
³
X2
− 2XE (X) + E (X)2
´
= E
¡
X2
¢
− 2 [E (X)]2
+ [E (X)]2
= E
¡
X2
¢
− [E (X)]2
= m2 − [m1]2
6](https://image.slidesharecdn.com/cours-stat2-kharrat-161102173803/85/Cours-stat2-kharrat-6-320.jpg)
![4.2 Variance d’une variable aléatoire discrète
On appelle variance de X et on note, V (X) ou σ2
X, le nombre réel positif, s’il existe défini par :
V (X) = σ2
X = E (X − E (X))2
=
P
x∈X(Ω)
(x − E (X))2
P (X = x)
=
P
x∈X(Ω)
x2
P (X = x) − 2E (X)
P
x∈X(Ω)
xP (X = x) + E (X)
2 P
x∈X(Ω)
P (X = x)
= E
¡
X2
¢
− [E (X)]2
4.2.1 Propriétés de la variance
a/ La variance d’une constante est nulle :
V (a) = E (a − E (a))2
= E (a − a)2
= 0
b/ changement d’origine
contrairement à l’espérance, la variance ne change pas avec un changement d’origine.
V (X + b) = E ((X + b) − E (X + b))2
= E (X + b − E (X) − b)2
= E (X − E (X))2
= V (X)
c/ changement d’échelle
V (aX) = E ((aX) − E (aX))
2
= E ((aX) − aE (X))
2
= E [a (X − E (X))]
2
= a2
E (X − E (X))
2
= a2
V (X)
b/ Théorème de Koenig
Ce théorème stipule que la variance est égale à la différence entre le moment non centré d’ordre 2 et le carré
du moment centré d’ordre 1 :
V (X) = E (X − E (X))2
= E
¡
X2
¢
− 2 [E (X)]2
+ [E (X)]2
= E
¡
X2
¢
− [E (X)]2
= m2 − [m1]2
Application à l’exemple 2 :
X : 0 1 2
Pi = P(X = xi) :
1
4
1
2
1
4
E (X) =
P
x∈X(Ω)
xP (X = x) = 0 ×
1
4
+ 1 ×
1
2
+ 2 ×
1
4
= 1
E
¡
X2
¢
=
P
x∈X(Ω)
x2
P (X = x) = 0 ×
1
4
+ 1 ×
1
2
+ 4 ×
1
4
=
3
2
V (X) = E
¡
X2
¢
− [E (X)]
2
=
3
2
− (1)
2
=
1
2
Si Y = 2X + 1, alors
E (Y ) = E (2X + 1) = 2E (X) + 1 = 3 et V (Y ) = V (2X + 1) = 4V (X) = 2
7](https://image.slidesharecdn.com/cours-stat2-kharrat-161102173803/85/Cours-stat2-kharrat-7-320.jpg)
![Deuxième partie
Variable aléatoire continue
1 Définition
Une variable aléatoire continue est une application X de Ω dans l’ensemble des réels R, telle que X (Ω) soit un
intervalle de R (c.-à-d. X (Ω) est un ensemble infini non dénombrable)
Par exemple, si X est telle que X (Ω) = [a, b] ⊂ R, ceci signifie que X prend toutes les valeurs réelles comprises
entre a et b. Dans ce cas, il n’est pas possible d’énumérer tous les éléments de X (Ω) et de calculer leur probabilité.
Pour une variable aléatoire continue, les éventualités sont si nombreuses qu’intuitivement, on est amené à attribuer
à chacune des valeurs une probabilité nulle. Cependant, on peut calculer la probabilité d’obtenir une valeur appar-
tenant à un intervalle donné [P (c ≤ X < d) = F (d)−F (c)] ou inférieure à une valeur donnée [P (X < x) = F (x)].
le fait de privilégier les événements décrits à l’aide d’intervalles, montre l’importance de la fonction de répartition
pour une variable aléatoire continue.
Exemple :
Soit l’expérience qui consiste à lancer des fléchettes vers une cible circulaire de rayon r et à s’intéresser aux points
de contact de la fléchette avec le plan de la cible. Dans ce cas, l’univers Ω est un ensemble infini non dénombrable :
Ω =
©
(x, y) /x2
+ y2
≤ r2
ª
, les couples (x, y) désignent les coordonnées des points de contacts.
Soit X la variable aléatoire définie par "la distance qui sépare le point de contact du centre de la cible".
L’ensemble des valeurs possibles de X est donc : X (Ω) = [0, r] .
X est une variable aléatoire continue puisqu’elle peut prendre n’importe quelle valeur à l’intérieure de l’intervalle
[0, r] .
{ }2 2 2
( , )/x y x ryΩ = + ≤
( ) [ ]0,X rΩ = ⊂ R
. r
d
x
y
point de contact, entre la fléchette et la cible, de coordonnées (x,y)
X
2 Fonction de répartition d’une variable aléatoire continue
2.1 Définition
Une variable aléatoire continue est caractérisée par sa fonction de répartition continue sur R, la définition de
cette dernière est identique à celle d’une variable discrète mais sa formulation mathématique change
F : R −→ [0, 1]
x 7−→ F (x) = P (X < x) =
R x
−∞
f(t)dt
où f(t) est appelée densité de probabilité de la variable aléatoire X
8](https://image.slidesharecdn.com/cours-stat2-kharrat-161102173803/85/Cours-stat2-kharrat-8-320.jpg)
![2.2 Propriétés de la fonction de répartition
a/ ∀x ∈ R, 0 ≤ F (x) ≤ 1
b/ F est une fonction croissante et vérifie lim
x→−∞
F (x) = 0 et lim
x→+∞
F (x) = 1. [si X (Ω) = R, la courbe de F
admet comme asymptotes horizontales les droites (y = 0) et (y = 1) .
c/ F est une fonction continue et dérivable presque partout
d/ Probabilité attachée à un point
Soit x et x + ε (ε > 0) deux réels quelconques, on a
P (x ≤ X < x + ε) = F (x + ε) − F (x)
Si on fait tendre ε vers 0, l’intervalle [x, x + ε[ se réduit à la seule valeur {x} . Dans ces conditions :
P (X = x) = lim
ε→0
P (x ≤ X < x + ε) = lim
ε→0
F (x + ε) − F (x)
La continuité de F entraîne donc lim
ε→0
F (x + ε) = F (x)
D’où P (X = x) = F (x) − F (x) = 0.
Pour une variable aléatoire continue, la probabilité d’observer une valeur réelle x donnée est donc nulle
e/ Probabilité attachée à un intervalle
P (X ∈ [a, b]) = P (a ≤ X ≤ b) = P (a < X ≤ b) = P (a ≤ X < b) = P (a < X < b) = F (b) − F (a)
=
R b
−∞
f(t)dt −
R a
−∞
f(t)dt
=
R b
a
f(t)dt
2.3 Représentation graphique de la fonction de répartition d’une v.a.c
La courbe représentative de la fonction de répartition d’une V.A.C a l’allure suivante :
1y =
( )F x
xo
( )si X Ω = R
1y =
( )F x
xo
( ) [ ]si ,X a bΩ =
a b
3 Densité de probabilité
3.1 Définition
Soit X une variable aléatoire continue de fonction de répartition F (x) .
La connaissance de la fonction de répartition nous permet de calculer la probabilité de voir X prendre une valeur
à l’intérieure de n’importe quel intervalle de bornes x et x + ∆x (x ∈ X (Ω)). En effet :
P (x < X < x + ∆x) = F (x + ∆x) − F (x) .
La probabilité moyenne de l’intervalle par unité de longueur est donné par :
P (x < X < x + ∆x)
∆x
=
F (x + ∆x) − F (x)
∆x
(∆x étant la longueur de l’intervalle [x, x + ∆x] .
On appelle densité de probabilité f (.) au point x, la valeur limite de probabilité moyenne sur l’intervalle
[x, x + ∆x] lorsque la longueur ∆x de cet intervalle tend vers 0 :
f (x) = lim
∆x→0
F (x + ∆x) − F (x)
∆x
= F0
(x)
Conséquence :
9](https://image.slidesharecdn.com/cours-stat2-kharrat-161102173803/85/Cours-stat2-kharrat-9-320.jpg)
![La probabilité pour que la variable aléatoire X prenne une valeur x à l’intérieure d’un intervalle infinitésimal de
longueur dx est égale au produit f (x) dx, appelé probabilité élémentaire.
dx infinitésimal ⇒
F (x + dx) − F (x)
dx
= f (x) ⇒ F (x + dx) − F (x) = f (x) dx
⇒ P (x < X < x + dx) = f (x) dx
La probabilité attachée à un intervalle [a, b] apparaît donc comme la somme, prise entre a et b, des probabilités
élémentaires :
P (a < X < b) =
R b
a
f(x)dx = F (b) − F (a)
a bdx
f(x)
probabilité élémentaire : f(x)dx
3.2 Propriétés de la fonction densité
a/ ∀x ∈ R, f (x) ≥ 0.
F (x) étant une fonction croissante, sa dérivé F0
(x), c.-à-d. la fonction densité f(x), est donc positive ou nulle.
b/
R +∞
−∞
f(x)dx = P (X ∈ R) = P (Ω) = 1
ou encore
R +∞
−∞
f(x)dx = lim
b→+∞
R b
−∞
f(x)dx = lim
b→+∞
F (b) = 1
Remarque : les propriétés a/ et b/ seront utilisées pour montrer qu’une fonction f(x) est une densité de
probabilité.
d/ La densité de probabilité f (x) est une fonction continue sur R, sauf éventuellement en un nombre fini de
points
c/ Puisque lim
x→−∞
F (x) = 0 et lim
x→+∞
F (x) = 1, alors
µ
lim
x→±∞
F (x)
¶0
= 0
⇔ lim
x→±∞
F0
(x) = lim
x→±∞
f (x) = 0
d/ La courbe de la fonction densité f (x) prend, parmi beaucoup d’autres les allures suivantes :
f(x)
x
( )si X Ω = R
f(x)
( ) [ ]si ,X a bΩ =
a b
Exemple 1 :
Soit X une variable aléatoire continue ne prenant que des valeurs comprises entre 2 et 4, et dont la densité de
probabilité est égale à f (x) = 1 − kx.
Déterminer la constante k et en déduire la fonction de répartition ?
10](https://image.slidesharecdn.com/cours-stat2-kharrat-161102173803/85/Cours-stat2-kharrat-10-320.jpg)
![Solution :
Il faut que f (x) ≥ 0 et
R +∞
−∞
f(x)dx = 1
f (x) ≥ 0 ⇒ kx < 1 ⇒ k <
1
x
, or 2 ≤ x ≤ 4 ⇒
1
4
≤
1
x
≤
1
2
, donc k <
1
4
.
R +∞
−∞
f(x)dx = =
R 2
−∞
f(x)
|{z}
=0
dx +
R 4
2
f(x)
|{z}
=(1−kx)
dx +
R +∞
4
f(x)
|{z}
=0
dx
=
R 4
2
(1 − kx)dx =
∙
x −
1
2
kx2
¸4
2
= 2 − 6k
R +∞
−∞
f(x)dx = 1 ⇔ 2 − 6k = 1 donc k =
1
6
La densité de probabilité de X est donnée par : f (x) =
(
1 −
x
6
si x ∈ [2, 4]
0 sinon
On a par définition F : R −→ [0, 1]
x 7−→ F (x) = P (X < x) =
R x
−∞
f(t)dt
Pour x < 2 F (x) =
R x
−∞
f(t)dt = 0
Pour 2 ≤ x ≤ 4 F (x) =
R x
−∞
f(t)dt =
R 2
−∞
f(t)dt +
R x
2
f(t)dt =
R x
2
(1 −
t
6
)dt =
∙
t −
1
12
t2
¸x
2
= x −
x2
12
−
5
3
Pour x > 4 F (x) =
R x
−∞
f(t)dt =
R 2
−∞
f(t)dt +
R 4
2
f(t)dt +
R x
4
f(t)dt =
R 4
2
(1 −
t
6
)dt = 1
⇒ F (x) =
⎧
⎪⎨
⎪⎩
0 si x < 2
x −
x2
12
−
5
3
si 2 ≤ x ≤ 4
1 si x > 4
Exemple 2 :
Soit X une variable aléatoire continue de fonction de répartition :
F (x) =
½
1 − e−x
si x ≥ 0
0 sinon
Déterminer la densité de probabilité de X.
On sait que f (x) = F0
(x)
f (x) = (1 − e−x
)
0
= e−x
si x ≥ 0
f (x) = 0 sinon
4 Les paramètres descriptifs d’une distribution continue
4.1 Espérance mathématique
On appelle espérance mathématique de la V.A.C X, et on note E (X) , le nombre réel s’il existe défini par :
E (X) =
R +∞
−∞
xf(x)dx
L’existence de E (X) est liée à la convergence de l’intégrale.
4.1.1 Espérance mathématique d’une fonction de X
Soit X une variable aléatoire continue sur laquelle on applique une fonction numérique quelconque ψ.
Si la fonction ψ admet une espérance mathématique, alors :
E (ψ (X)) =
R +∞
−∞
ψ (x) f(x)dx
a/ Les moments non centrés : ψ (X) = Xk
Le moment non centré d’ordre k de X, noté mk est défini par :
mk = E
¡
Xk
¢
=
R +∞
−∞
xk
f(x)dx
pour k = 0 m0 = E (1) = 1
pour k = 1 m1 = E (X) ⇒ l’espérance est le moment non centré d’ordre 1
pour k = 2 m2 = E
¡
X2
¢
=
R +∞
−∞
x2
f(x)dx
11](https://image.slidesharecdn.com/cours-stat2-kharrat-161102173803/85/Cours-stat2-kharrat-11-320.jpg)
![b/ Les moments centrés : ψ (X) = [X − E (X)]
k
Le moment centré d’ordre k de X, noté µk est défini par :
µk (X) = E [X − E (X)]k
=
R +∞
−∞
(x − E (X))k
f(x)dx
pour k = 0 µ0 = E (1) = 1
pour k = 1 µ1 = E (X − E (X)) = 0
pour k = 2 µ2 = E (X − E (X))2
=
R +∞
−∞
³
x2
− 2xE (X) + E (X)2
´
f(x)dx
=
R +∞
−∞
x2
f(x)dx − 2E (X)
R +∞
−∞
f(x)dx + E (X)
2 R +∞
−∞
f(x)dx
= E
¡
X2
¢
− 2E (X)
2
+ E (X)
2
= E
¡
X2
¢
− [E (X)]2
= m2 − [m1]2
4.1.2 Propriétés de l’espérance mathématique
a/ l’espérance mathématique d’une constante est égale à la constante elle même.
E (a) =
R +∞
−∞
af(x)dx = a
Z +∞
−∞
f(x)dx
| {z }
1
= a
b/ changement d’origine :
E (X + b) =
R +∞
−∞
(x + b) f(x)dx =
R +∞
−∞
xf(x)dx + b
R +∞
−∞
f(x)dx = E (X) + b
E (X + b) = E (X) + b
c/ changement d’échelle :
E (aX) =
R +∞
−∞
axf(x)dx = a
R +∞
−∞
xf(x)dx = aE (X)
E (aX) = aE (X)
b/ et c/ =⇒ E (aX + b) = aE (X) + b
d/ La somme des écarts, pondérées par les probabilités élémentaires, entre les valeurs x et l’espérance mathéma-
tique E (X) est nulle :
E (X − E (X)) =
R +∞
−∞
(x − E (X)) f(x)dx =
R +∞
−∞
xf(x)dx − E (X)
R +∞
−∞
f(x)dx
= E (X) − E (X) = 0
E (X − E (X)) = 0
4.2 Variance d’une variable aléatoire continue
On appelle variance de X et on note, V (X) ou σ2
X, le nombre réel positif, s’il existe, défini par :
V (X) = σ2
X = E (X − E (X))2
=
R +∞
−∞
(x − E (X))
2
f(x)dx
= µ2 = E
¡
X2
¢
− [E (X)]2
= m2 − [m1]2
12](https://image.slidesharecdn.com/cours-stat2-kharrat-161102173803/85/Cours-stat2-kharrat-12-320.jpg)
![Troisième partie
La fonction génératrice des moments
1 Définition
Soit X une variable aléatoire. On appelle fonction génératrice des moments de la v.a. X, la fonction MX (t)
définie par :
MX (t) = E
¡
etX
¢
=
P
x∈X(Ω)
etx
P (X = x) si X est une v.a. discrète
=
R +∞
−∞
etx
f(x)dx si X est une v.a. continue
L’intérêt de la fonction génératrice des moments réside dans la possibilité de calculer rapidement les moments
non centrés d’ordre k.
1.1 Propriétés de la fonction génératrice des moments
a/ MX (t) > 0 et MX (0) = 1
∀X, etX
> 0 ⇒ MX (t) = E
¡
etX
¢
> 0
MX (0) = E
¡
e0
¢
= E (1) = 1
b/ Soit Y = aX + b
MY (t) = E
¡
etY
¢
= E
¡
et(aX+b)
¢
= E
¡
eatX
.etb
¢
= etb
E
¡
eatX
¢
= etb
.MX (at) .
c/ La dérivée première de MX (t) en t = 0 est égale à l’espérance mathématique de X
∂MX (t)
∂t
¯
¯
¯
¯
t=0
= E (X)
— Cas où X est une v.a. discrète :
∂MX (t)
∂t
=
∂
P
x∈X(Ω)
etx
P (X = x)
∂t
=
P
x∈X(Ω)
P (X = x)
∂etx
∂t
=
P
x∈X(Ω)
xetx
P (X = x)
⇒
∂MX (t)
∂t
¯
¯
¯
¯
t=0
=
P
x∈X(Ω)
xe0x
P (X = x) =
P
x∈X(Ω)
xP (X = x) = E (X)
— Cas où X est une v.a. continue
∂MX (t)
∂t
=
∂
R +∞
−∞
etx
f(x)dx
∂t
=
R +∞
−∞
f(x)dx
∂etx
∂t
=
R +∞
−∞
xetx
f(x)dx
⇒
∂MX (t)
∂t
¯
¯
¯
¯
t=0
=
R +∞
−∞
xf(x)dx = E (X)
Plus généralement, la dérivée d’ordre k de la fonction MX (t) , évaluée au point t = 0, est égale au moment
non centré d’ordre k :
∂k
MX (t)
∂tk
¯
¯
¯
¯
t=0
= E
¡
Xk
¢
= mk, k ∈ N
⇒ la variance de X est donc :
V (X) = E
¡
X2
¢
− [E (X)]
2
=
∂2
MX (t)
∂t2
¯
¯
¯
¯
t=0
−
∙
∂MX (t)
∂t
¯
¯
¯
¯
t=0
¸2
Exemple1 :
Soit X une variable aléatoire de loi de probabilité : P (X = x) =
1
(2)
x+1 x ∈ N
Calculer la fonction génératrice des moments. En déduire E (X) et V (X) .
Solution :
X est donc une variable aléatoire discrète.
⇒ MX (t) = E
¡
etX
¢
=
P
x∈X(Ω)
etx
P (X = x) =
+∞P
x=0
etx
µ
1
2
¶x+1
=
1
2
+∞P
x=0
µ
et
2
¶x
13](https://image.slidesharecdn.com/cours-stat2-kharrat-161102173803/85/Cours-stat2-kharrat-13-320.jpg)
![+∞P
x=0
µ
et
2
¶x
est une série géométrique qui ne converge que si
et
2
< 1
µ
et
2
> 0 ∀t
¶
En effet,
+∞P
x=0
µ
et
2
¶x
= lim
n→∞
nP
x=0
µ
et
2
¶x
= lim
n→∞
Ã
1 +
et
2
+
µ
et
2
¶2
+ · · · +
µ
et
2
¶n
!
= lim
n→∞
⎛
⎜
⎜
⎜
⎝
1 −
µ
et
2
¶n+1
1 −
et
2
⎞
⎟
⎟
⎟
⎠
=
1
1 −
et
2
si t < Log2
⇒ MX (t) =
1
2
1
1 −
et
2
= (2 − et
)
−1
si t < Log2
∂MX (t)
∂t
=
∂ (2 − et
)
−1
∂t
= et
(2 − et
)
−2
⇒ E (X) =
∂MX (t)
∂t
¯
¯
¯
¯
t=0
= 1
∂2
MX (t)
∂t2
= et
(2 − et
)
−2
+ et
h
−2 (−et
) (2 − et
)
−3
i
= et
(2 − et
)
−2
+ 2e2t
(2 − et
)
−3
= et
(2 − et
)
−2
h
1 + 2et
(2 − et
)
−1
i
⇒ E
¡
X2
¢
=
∂2
MX (t)
∂t2
¯
¯
¯
¯
t=0
= 3 ⇒ V (X) = E
¡
X2
¢
− [E (X)]
2
= 2
Exemple2 :
Soit θ une constante strictement positive et soit f(x) =
½
θe−θx
si x ≥ 0
0 sinon
1. Vérifier que f est bien une densité de probabilité.
2. Calculer la fonction génératrice des moments. En déduire E (X) et V (X) .
Solution :
1. On a f(x) ≥ 0 ∀x ∈ R
R +∞
−∞
f(x)dx =
R 0
−∞
f(x)dx +
R +∞
0
f(x)dx =
R +∞
0
θe−θx
dx = −
£
e−θx
¤+∞
0
= 1
f est bien la densité de probabilité d’une variable aléatoire X.
2. MX (t) =
R +∞
−∞
etx
f(x)dx =
R 0
−∞
etx
f(x)dx +
R +∞
0
etx
f(x)dx =
R +∞
0
etx
θe−θx
dx =
R +∞
0
θe(t−θ)x
dx
⇔ MX (t) = θ
R +∞
0
e(t−θ)x
dx = θ
∙
1
t − θ
e(t−θ)x
¸+∞
0
=
−θ
t − θ
=
θ
θ − t
si t < θ.
( il faut que t < θ ⇔ t − θ < 0 pour que lim
x→+∞
e(t−θ)x
= 0 sinon l’intégrale ne serait pas convergente)
∂MX (t)
∂t
=
θ
(θ − t)
2 ⇒ E (X) =
∂MX (t)
∂t
¯
¯
¯
¯
t=0
=
1
θ
et
∂2
MX (t)
∂t2
=
2θ
(θ − t)
3 ⇒ E
¡
X2
¢
=
∂2
MX (t)
∂t2
¯
¯
¯
¯
t=0
=
2
θ2
⇒ V (X) = E
¡
X2
¢
− [E (X)]
2
=
2
θ2 −
1
θ2 =
1
θ2 .
14](https://image.slidesharecdn.com/cours-stat2-kharrat-161102173803/85/Cours-stat2-kharrat-14-320.jpg)


![La fonction h étant strictement monotone sur X (Ω) , elle admet donc une réciproque h−1
sur Y (Ω) . (h (X (Ω)) =
Y (Ω))
⇒ ∀y ∈ Y (Ω) , FY (y) = P (Y < y) = P (h(X) < y)
Or h peut être strictement croissante ou décroissante sur X (Ω) :
• si h est strictement croissante sur X (Ω) alors h−1
l’est aussi sur Y (Ω) et l’on peut écrire :
⇒ ∀y ∈ Y (Ω) , FY (y) = P (Y < y) = P (h(X) < y) = P
¡
X < h−1
(y)
¢
= FX
¡
h−1
(y)
¢
La fonction densité de Y, fY , s’obtient par dérivation de FY .
∀y ∈ Y (Ω) fY (y) = F0
Y (y) = F0
X
¡
h−1
(y)
¢
.
¡
h−1
(y)
¢0
= fX
¡
h−1
(y)
¢
.
∂
¡
h−1
(y)
¢
∂y
, avec
∂
¡
h−1
(y)
¢
∂y
> 0 (puisque h−1
est strictement %) et fX
¡
h−1
(y)
¢
≥ 0 (fonction densité)
y
Y y<
⎧⎪⎪⎪⎪⎪⎨
⎪⎪⎪⎪⎪⎩
Y
X
h(X)
h-1
(y)=x
( )1X h y−<
( )X Ω
( )Y Ω
Exemple :
Soit X une variable aléatoire continue de densité de probabilité :
fX(x) =
( 1
3
si 0 ≤ x ≤ 3
0 sinon
et soit Y une variable aléatoire fonction de X définie par : Y = h(X) = 2X. Déterminer la densité de probabilité
fY de Y ?
A partir de la densité de probabilité de X, on a X (Ω) = [0, 3] ⇒ Y (Ω) = h [X (Ω)] = [0, 6]
⇒ ∀y ∈ Y (Ω) = [0, 6] , FY (y) = P (Y < y) = P (h(X) < y) = P (2X < y) = P
⎛
⎜
⎜
⎝X <
y
2|{z}
h−1(y)
⎞
⎟
⎟
⎠ = FX
³y
2
´
La fonction densité de Y, fY , s’obtient par dérivation de FY :
∀y ∈ [0, 6] fY (y) = F0
Y (y) = fX
³y
2
´
.
µ
1
2
¶
Or fX
³y
2
´
=
( 1
3
si 0 ≤ y ≤ 6
0 sinon
, on a finalement :
fY (y) =
( 1
6
si 0 ≤ y ≤ 6
0 sinon
• si h est strictement décroissante sur X (Ω) alors h−1
l’est aussi sur Y (Ω) et l’on peut écrire :
17](https://image.slidesharecdn.com/cours-stat2-kharrat-161102173803/85/Cours-stat2-kharrat-17-320.jpg)
![⇒ ∀y ∈ Y (Ω) , FY (y) = P (Y < y) = P (h(X) < y) = P
¡
X > h−1
(y)
¢
= 1 − P
¡
X ≤ h−1
(y)
¢
= 1 − FX
¡
h−1
(y)
¢
La fonction densité de Y, fY , s’obtient par dérivation de FY
∀y ∈ Y (Ω) fY (y) = F0
Y (y) = −F0
X
¡
h−1
(y)
¢
.
¡
h−1
(y)
¢0
= −fX
¡
h−1
(y)
¢
.
∂
¡
h−1
(y)
¢
∂y
, avec
∂
¡
h−1
(y)
¢
∂y
< 0 (puisque h−1
est strictement &)
y
Y y<
⎧⎪⎪⎪⎪⎪⎪⎨
⎪⎪⎪⎪⎪⎪⎩
Y
X
h(X)
h-1
(y)=x
( )1X h y−>
( )X Ω
( )Y Ω
Exemple :
Soit X une variable aléatoire continue de densité de probabilité :
fX(x) =
(
1
3
si 0 ≤ x ≤ 3
0 sinon
et soit Y une variable aléatoire fonction de X définie par : Y = h(X) = −2X. Déterminer la densité de
probabilité fY de Y ?
A partir de la densité de probabilité de X, on a X (Ω) = [0, 3] ⇒ Y (Ω) = h [X (Ω)] = [−6, 0]
⇒ ∀y ∈= [−6, 0] , FY (y) = P (Y < y) = P (h(X) < y) = P
⎛
⎜
⎜
⎝X > −
y
2|{z}
h−1(y)
⎞
⎟
⎟
⎠ = 1−P
³
X ≤ −
y
2
´
= 1−FX
³
−
y
2
´
La fonction densité de Y, fY , s’obtient par dérivation de FY :
∀y ∈= [−6, 0] fY (y) = F0
Y (y) =
h
1 − FX
³
−
y
2
´i0
= −fX
³
−
y
2
´
.
µ
−
1
2
¶
=
1
2
fX
³
−
y
2
´
Or fX
³
−
y
2
´
=
(
1
3
si − 6 ≤ y ≤ 0
0 sinon
, on a finalement :
fY (y) =
(
1
6
si − 6 ≤ y ≤ 0
0 sinon
D’une manière générale, si h est une fonction strictement monotone, alors la densité de probabilité de Y est
donnée par :
fY (y) =
⎧
⎪⎨
⎪⎩
fX
¡
h−1
(y)
¢
.
¯
¯
¯
¯
¯
∂
¡
h−1
(y)
¢
∂y
¯
¯
¯
¯
¯
∀y ∈ Y (Ω)
0 sinon
2.2.2 Cas d’une transformation non monotone
On se limitera ici aux cas des deux transformations h (X) = X2
et h (X) = |X|
18](https://image.slidesharecdn.com/cours-stat2-kharrat-161102173803/85/Cours-stat2-kharrat-18-320.jpg)
![• Cas de la transformation h (X) = X2
.
Soit X une variable aléatoire continue de densité de probabilité fX et de fonction de répartition FX, et soit
Y = h(X) = X2
une variable aléatoire fonction de X.
h(X) = X2
est une fonction non monotone sur R, elle est strictement croissante sur R+ et strictement
décroissante sur R−
Y y<
⎧⎪⎪⎪⎪⎪⎪⎨
⎪⎪⎪⎪⎪⎪⎩
Y
X
h(X)=X2
y yX− < <
y− y
Soit FY la fonction de répartition de Y :
⇒ ∀y ∈ Y (Ω) , FY (y) = P (Y < y) = P (h(X) < y) = P
¡
X2
< y
¢
= P
¡
|X| <
√
y
¢
= P
¡
−
√
y < X <
√
y
¢
= P
¡
X <
√
y
¢
− P
¡
X ≤ −
√
y
¢
= FX
¡√
y
¢
− FX
¡
−
√
y
¢
La fonction densité de Y, fY , s’obtient par dérivation de FY
∀y ∈ Y (Ω) {0} fY (y) = F0
Y (y) = F0
X
¡√
y
¢
.
¡√
y
¢0
− F0
X
¡
−
√
y
¢
.
¡
−
√
y
¢0
=
1
2
√
y
fX
¡√
y
¢
+
1
2
√
y
fX
¡
−
√
y
¢
=
1
2
√
y
£
fX
¡√
y
¢
+ fX
¡
−
√
y
¢¤
La densité de probabilité de Y est donc donnée par :
fY (y) =
⎧
⎨
⎩
1
2
√
y
£
fX
¡√
y
¢
+ fX
¡
−
√
y
¢¤
∀y ∈ Y (Ω) {0}
0 sinon
Exemple :
Soit X une variable aléatoire de densité de probabilité :
fX (x) =
(
1
2
si x ∈ [−1, 1]
0 sinon
Déterminer la densité de probabilité de Y = X2
. En déduire FY (y)
Solution :
On a X (Ω) = [−1, 1] =⇒ Y (Ω) = [0, 1]
⇒ ∀y ∈ [0, 1] FY (y) = P (Y < y) = P
¡
X2
< y
¢
= P
¡
−
√
y < X <
√
y
¢
= FX
¡√
y
¢
− FX
¡
−
√
y
¢
La fonction densité de Y, fY , s’obtient par dérivation de FY
⇒ ∀y ∈ ]0, 1] fY (y) = F0
Y (y) =
1
2
√
y
£
fX
¡√
y
¢
+ fX
¡
−
√
y
¢¤
On a y ∈ ]0, 1] ⇒
√
y ∈ ]0, 1] et −
√
y ∈ [−1, 0[ ⇒ fX
¡√
y
¢
= fX
¡
−
√
y
¢
=
1
2
⇒ ∀y ∈ ]0, 1] fY (y) =
1
2
√
y
19](https://image.slidesharecdn.com/cours-stat2-kharrat-161102173803/85/Cours-stat2-kharrat-19-320.jpg)
![La densité de probabilité de Y est donc donnée par :
fY (y) =
⎧
⎨
⎩
1
2
√
y
si y ∈ ]0, 1]
0 sinon
• Cas de la transformation h (X) = |X|
Soit X une variable aléatoire continue et soit Y la variable aléatoire définie par Y = h(X) = |X| .
h(X) = |X| est également une fonction non monotone sur R, elle est strictement croissante sur R+ et stricte-
ment décroissante sur R−
Y y<
⎧⎪⎪⎪⎪⎨
⎪⎪⎪⎪⎩
Y
X
y X y− < <
y− y
( )h X X=
Soit FY la fonction de répartition de Y :
⇒ ∀y ∈ Y (Ω) , FY (y) = P (Y < y) = P (h(X) < y) = P (|X| < y) = P (−y < X < y)
= P (X < y) − P (X ≤ −y)
= FX (y) − FX (−y)
La fonction densité de Y, fY , s’obtient par dérivation de FY
∀y ∈ Y (Ω) fY (y) = F0
Y (y) = F0
X (y) . (y)0
− F0
X (−y) . (−y)0
= fX (y) + fX (−y)
La densité de probabilité de Y est donc donnée par :
fY (y) =
½
fX (y) + fX (−y) ∀y ∈ Y (Ω)
0 sinon
Exemple :
Soit X une variable aléatoire de densité de probabilité :
fX (x) =
( 1
2
si x ∈ [−1, 1]
0 sinon
Déterminer la densité de probabilité de Y = |X| . En déduire FY (y)
Solution :
On a X (Ω) = [−1, 1] =⇒ Y (Ω) = [0, 1]
⇒ ∀y ∈ [0, 1] , FY (y) = P (Y < y) = P (|X| < y) = P (−y < X < y)
= P (X < y) − P (X ≤ −y)
= FX (y) − FX (−y)
La fonction densité de Y, fY , s’obtient par dérivation de FY
∀y ∈ [0, 1] , fY (y) = F0
Y (y) = fX (y) + fX (−y) =
1
2
+
1
2
= 1.
La densité de probabilité de Y est donc donnée par :
20](https://image.slidesharecdn.com/cours-stat2-kharrat-161102173803/85/Cours-stat2-kharrat-20-320.jpg)
![fY (y) =
½
1 si y ∈ [0, 1]
0 sinon
On a par définition FY (y) : R −→ [0, 1]
y 7−→ FY (y) = P (Y < y) =
R y
−∞
f(t)dt
Pour y < 0 ⇒ fY (y) = 0 ⇒ FY (y) =
R y
−∞
f(t)dt = 0
Pour 0 ≤ y < 1 ⇒ fY (y) = 1 ⇒ FY (y) =
R y
−∞
f(t)dt =
R 0
−∞
f(t)dt +
R y
0
f(t)dt =
R y
0
f(t)dt =
R y
0
1dt = [t]
y
0 = y
Pour y ≥ 1 ⇒ fY (y) = 0 ⇒ FY (y) =
R y
−∞
f(t)dt =
R 0
−∞
f(t)dt +
R 1
0
f(t)dt +
R y
1
f(t)dt =
R 1
0
f(t)dt = [t]
1
0 = 1
La fonction de répartition se Y est donc :
FY (y) =
⎧
⎨
⎩
0 si y < 0
y si 0 ≤ y < 1
1 si y ≥ 1
21](https://image.slidesharecdn.com/cours-stat2-kharrat-161102173803/85/Cours-stat2-kharrat-21-320.jpg)
![K&M http ://stat.fateback.com
Chapitre 2
Les lois de probabilités usuelles
Première partie
Les lois discrètes
1 La loi de Bernoulli : X Ã B (1, p)
1.1 Expérience de Bernoulli
Une expérience de Bernoulli est une expérience aléatoire simple au terme de laquelle 2 résultats seulement sont
possibles et mutuellement exclusifs. Ces deux résultats sont souvent désignés par l’appellation “succès” et “échec”.
Exemple : l’expérience qui consiste à tirer une boule dans une urne contenant des boules rouges et des boules
non rouges est une expérience de Bernoulli : Ω = {R, NR} .
1.2 Définition
Soit X la variable aléatoire associée à cette expérience. X prend la valeur 1 lorsque le résultat est un succès et
0 lorsque le résultat est un échec : X (Ω) = {0, 1} . Soit p la probabilité d’obtenir un succès et q = (1 − p) celle
d’obtenir un échec. La loi de probabilité de X est donnée par :
X : 0 1
P(X = x) : q = (1 − p) p
⇔ P (X = x) = px
(1 − p)1−x
, x ∈ {0, 1} .
La variable aléatoire ainsi définie est dite variable de Bernoulli et on note X Ã B (1, p) ou B (p)
Suite de l’exemple :
Si le nombre de boules rouges est égal au double de celui des boules non rouges, et si X prend la valeur 1
lorsque la boule tirée est rouge et 0 lorsque la boule est non rouge, alors la loi de probabilité de X est donnée par :
P (X = x) =
⎧
⎨
⎩
µ
2
3
¶x µ
1
3
¶1−x
si x ∈ {0, 1}
0 sinon
et on note X Ã B
µ
1,
2
3
¶
1.3 Paramètres descriptifs
1.3.1 Espérance mathématique
E (X) =
P
x∈X(Ω)
x.P (X = x) =
1P
x=0
x.px
. (1 − p)
1−x
= p
E (X) = p
Remarque : les moments non centrés d’ordre k (k ∈ N∗
) sont tous égals à p.
E
¡
Xk
¢
=
1P
x=0
xk
.px
. (1 − p)
1−x
= (1)
k
p1
. (1 − p)
0
= p ⇒ pour k = 2, E
¡
X2
¢
= p
1.3.2 Variance
V (X) = E
¡
X2
¢
− [E (X)]
2
= p − p2
= p (1 − p) = pq.
V (X) = p (1 − p) = pq
1](https://image.slidesharecdn.com/cours-stat2-kharrat-161102173803/85/Cours-stat2-kharrat-22-320.jpg)
![1.4 Fonction génératrice des moments
MX (t) = E
¡
etX
¢
=
P
x∈X(Ω)
etx
P (X = x) =
1P
x=0
etx
px
(1 − p)
1−x
= (1 − p) + pet
= q + pet
.
MX (t) = q + pet
, ∀t ∈ R
Déduction de l’espérance et de la variance à partir de la F.G.M :
on a ∀k ∈ N∗
,
∂k
MX (t)
∂tk
= pet
⇒ E
¡
Xk
¢
=
∂k
MX (t)
∂tk
¯
¯
¯
¯
t=0
= p ⇒ E (X) = E
¡
X2
¢
= p.
⇒ V (X) = E
¡
X2
¢
− [E (X)]
2
= p − p2
= p (1 − p) = pq.
Tableau récapitulatif n◦
: 1
La loi de Bernoulli est la loi qui s’applique à des épreuves aléatoires
qui peuvent avoir seulement deux résultats possibles : “succès” et “échec”
X Ã B (1, p) ⇒ •X (Ω) = {0, 1}
•P (X = x) = px
(1 − p)1−x
x ∈ {0, 1}
•E (X) = p et V (X) = pq
•MX (t) = q + pet
, ∀t ∈ R
2](https://image.slidesharecdn.com/cours-stat2-kharrat-161102173803/85/Cours-stat2-kharrat-23-320.jpg)


![⇒ E(X) =
nP
x=1
n{x−1
n−1px
(1 − p)n−x
=
nP
x=1
n{x−1
n−1px−1
p (1 − p)(n−1)−(x−1)
= np
nP
x=1
{x−1
n−1px−1
(1 − p)(n−1)−(x−1)
posons y = x − 1
⇒ E(X) = np
n−1X
y=0
{y
n−1py
(1 − p)
(n−1)−y
| {z }
=1
;
n−1P
y=0
{y
n−1py
(1 − p)
(n−1)−y
=
P
y∈Y (Ω)
P(Y = y) où Y Ã B(n − 1, p)
⇒ E(X) = np (p + (1 − p))
n−1
= np
E(X) = np
2.3.2 Variance
V (X) = E (X − E (X))
2
= E
¡
X2
¢
− [E (X)]
2
or E
¡
X2
¢
=
P
x∈X(Ω)
x2
P (X = x) =
nP
x=0
x2
{x
npx
(1 − p)
n−x
= 0 +
nP
x=1
x2
{x
npx
(1 − p)n−x
=
nP
x=1
xn{x−1
n−1px−1
p (1 − p)(n−1)−(x−1)
= np
n−1P
y=0
(y + 1) {y
n−1py
(1 − p)(n−1)−y
, avec y = x − 1
= np
"
n−1P
y=0
y{y
n−1py
(1 − p)
(n−1)−y
+
n−1P
y=0
{y
n−1py
(1 − p)
(n−1)−y
#
n−1P
y=0
y{y
n−1py
(1 − p)(n−1)−y
= E(Y ) avec Y Ã B(n − 1, p) ⇒ E(Y ) = (n − 1) p
n−1P
y=0
{y
n−1py
(1 − p)(n−1)−y
= (p + (1 − p))n−1
= 1
⇒ E(X2
) = np [(n − 1) p + 1] = (np)
2
− np2
+ np
⇒ V (X) = E
¡
X2
¢
− [E (X)]2
= (np)2
− np2
+ np − (np)2
= np (1 − p) = npq
V (X) = npq
2.4 Fonction génératrice des moments
1`ere
méthode :
MX (t) = E
¡
etX
¢
=
P
x∈X(Ω)
etx
P (X = x) =
nP
x=0
etx
{x
npx
(1 − p)n−x
=
nP
x=0
{x
n (pet
)
x
(1 − p)n−x
= [pet
+ (1 − p)]
n
= [pet
+ q]
n
2`eme
méthode :
Une variable aléatoire qui suit la loi binomiale de paramètres (n, p) est une somme de n variables de Bernoulli
indépendantes de même paramètre p.
X Ã B(n, p) ⇔ X =
nP
i=1
Xi où les Xi sont indépendantes et Xi à B(1, p) ∀i : 1 . . . n.
Xi à B(1, p) ⇒ E (Xi) = p et V (Xi) = pq
Rappel :
E(
nP
i=1
Xi) =
nP
i=1
E (Xi) ∀Xi
V (
nP
i=1
Xi) =
nP
i=1
V (Xi)
E(
nQ
i=1
Xi) =
nQ
i=1
E (Xi)
⎫
⎪⎪⎬
⎪⎪⎭
seulement dans le cas où les Xi sont indépendantes
On a donc
E(X) = E(
nP
i=1
Xi) =
nP
i=1
E (Xi) =
nP
i=1
p = np
6](https://image.slidesharecdn.com/cours-stat2-kharrat-161102173803/85/Cours-stat2-kharrat-27-320.jpg)
![V (X) = V (
nP
i=1
Xi) =
nP
i=1
V (Xi) =
nP
i=1
pq = npq
MX (t) = E
¡
etX
¢
= E
³
et
Pn
i=1
Xi
´
= E
µ nQ
i=1
etXi
¶
=
nQ
i=1
E
¡
etXi
¢
puisque les Xi sont indépendantes
nQ
i=1
MXi (t) = [pet
+ q]
n
Déduction de l’espérance et de la variance à partir de la F.G.M :
∂MX (t)
∂t
= n (pet
) [pet
+ q]
n−1
⇒ E (X) =
∂MX (t)
∂t
¯
¯
¯
¯
t=0
= np
∂2
MX (t)
∂t2
= n
h
pet
[pet
+ q]
n−1
+ pet
h
(n − 1) pet
(pet
+ q)
n−2
ii
⇒ E
¡
X2
¢
=
∂2
MX (t)
∂t2
¯
¯
¯
¯
t=0
= n
h
p [p + q]
n−1
+ p
h
(n − 1) p (p + q)
n−2
ii
= n
£
p + (n − 1) p2
¤
⇒ V (X) = E
¡
X2
¢
− [E (X)]
2
= n
£
p + (n − 1) p2
¤
− (np)
2
= npq.
2.5 Stabilité de la loi binomiale par l’addition
Soient X1 et X2 deux variables aléatoires binomiales indépendantes telles que :
X1 Ã B(n1, p) et X2 Ã B(n2, p)
⇒ MX1 (t) = [pet
+ q]
n1
et MX2 (t) = [pet
+ q]
n2
Soit Y = X1+ X2 ⇒ MY (t) = E
¡
etY
¢
= E
¡
et(X1+X2)
¢
= E
¡
etX1
.etX2
¢
= E
¡
etX1
).E(etX2
¢
[X1etX2 sont indépendantes]
= MX1 (t) .MX2 (t) = [pet
+ q]
n1+n2
c’est la F.G.M. d’une binomiale (n1 + n2, p)
Conclusion :
Si k variables aléatoires indépendantes sont telles que Xi à B(ni, p) ∀i : 1 . . . k.
alors Y =
kP
i=1
Xi à B(
kP
i=1
ni, p)
2.6 Application
Une urne contient 5 boules dont 2 sont rouges (R) et les autres non rouges (N). On effectue 3 tirages indépendants
d’une boule chaque fois. Soit X le nombre de boules rouges extraites
1. Donner le support de X ainsi que sa loi de probabilité.
2. Calculer P(X = 2)
3. Calculer l’espérance et la variance de X
Solution :
1. Les tirages étant avec remise, on a X(Ω) = {0, 1, 2, 3}
p = P(tirer une boule rouge) =
2
5
et q = P(tirer une boule non rouge) =
3
5
X Ã B
µ
3,
2
5
¶
et on a P (X = x) =
⎧
⎨
⎩
{x
3
µ
2
5
¶x µ
3
5
¶3−x
si x ∈ {0, 1, 2, 3}
0 sinon
2. P(X = 2) = {2
3
µ
2
5
¶2 µ
3
5
¶
= 3 ×
µ
2
5
¶2 µ
3
5
¶
=
24
125
= 0, 192.
3. E (X) = np = 3 ×
2
5
=
6
5
et V (X) = 3 ×
2
5
×
3
5
=
18
25
7](https://image.slidesharecdn.com/cours-stat2-kharrat-161102173803/85/Cours-stat2-kharrat-28-320.jpg)
![Tableau récapitulatif n◦
: 2
La loi binomiale est utilisée lorsqu’on cherche à calculer la probabilité du nombre
de réalisations d’un événement à l’issue d’une successions de n essais indépendants
d’une épreuve aléatoire n’ayant que deux issues possibles, l’événement recherché
avec une probabilité p, l’autre avec une probabilité 1 − p.
X Ã B (n, p) ⇒ •X (Ω) = {0, 1, 2, . . . , n}
•P (X = x) = {x
npx
(1 − p)
n−x
x ∈ {0, 1, . . . , n}
•E (X) = np et V (X) = npq
•MX (t) = [q + pet
]
n
, ∀t ∈ R
X1 Ã B(n1, p) et X2 Ã B(n2, p) ⇒ X1 + X2 Ã B(n1 + n2, p)
Mots clès : tirage non exhaustif - tirages indépendants - tirages avec remise
8](https://image.slidesharecdn.com/cours-stat2-kharrat-161102173803/85/Cours-stat2-kharrat-29-320.jpg)
![3 La loi de Poisson2
: X Ã P (λ)
La loi de Poisson s’appelle encore la loi des petites probabilités ou loi des phénomènes rares. Elle est utilisée
pour décrire le comportement d’événements dont les chances de réalisations sont faibles.
3.1 Définition
On dit qu’une variable aléatoire X, à valeurs dans N, suit une loi de Poisson de paramètre λ si, λ étant un réel
strictement positif, la loi de X est définie par :
P (X = x) =
⎧
⎨
⎩
e−λ
.λx
x!
x ∈ N
0 sinon
Une loi de Poisson étant parfaitement définie par le paramètre λ, on écrit alors : X Ã P(λ).
On vérifie que
P
x∈X(Ω)
P (X = x) =
∞P
x=0
e−λ
.λx
x!
= e−λ
∞P
x=0
λx
x!
= e−λ
.eλ
= 1.
3.2 Paramètres descriptifs
3.2.1 Espérance mathématique
E(X) =
P
x∈X(Ω)
x.P (X = x) =
∞P
x=0
xe−λ λx
x!
=
∞P
x=1
e−λ λx
(x − 1)!
= λe−λ
∞P
x=1
λx−1
(x − 1)!
= λe−λ
eλ
= λ.
E(X) = λ
Le paramètre λ s’interprète comme le taux moyen avec lequel un phénomène particulier apparaît.
3.2.2 Variance
V (X) = E
¡
X2
¢
− [E (X)]2
1`ere
méthode :
E
¡
X2
¢
=
P
x∈X(Ω)
x2
.P (X = x) =
∞P
x=0
x2
.e−λ λx
x!
= 0 +
∞P
x=1
x.e−λ λx
(x − 1)!
= e−λ
∞P
x=1
(x − 1 + 1) .
λx
(x − 1)!
= e−λ
∞P
x=1
(x − 1)
λx
(x − 1)!
+ e−λ
∞P
x=1
λx
(x − 1)!
= 0 + e−λ
∞P
x=2
λx
(x − 2)!
+ e−λ
∞P
x=1
λx
(x − 1)!
= λ2
e−λ
∞P
x=2
λx−2
(x − 2)!
+ λe−λ
∞P
x=1
λx−1
(x − 1)!
= λ2
e−λ
eλ
+ λe−λ
eλ
= λ2
+ λ
⇒ V (X) = E
¡
X2
¢
− [E (X)]
2
= λ2
+ λ − λ2
= λ
V (X) = λ
2`eme
méthode :
E
¡
X2
¢
=
∞P
x=0
x2
.e−λ λx
x!
=
∞P
x=0
[x(x − 1) + x] .e−λ λx
x!
=
∞P
x=0
x.(x − 1).e−λ λx
x!
+
∞P
x=0
x.e−λ λx
x!
=
∞P
x=2
x.(x − 1).e−λ λx
x!
+
∞P
x=1
x.e−λ λx
x!
= λ2
e−λ
∞P
x=2
λx−2
(x − 2)!
+ λe−λ
∞P
x=1
λx−1
(x − 1)!
= λ2
e−λ
eλ
+ λe−λ
eλ
= λ2
+ λ
2 Siméon D. Poisson, mathématicien français (1781-1840)
9](https://image.slidesharecdn.com/cours-stat2-kharrat-161102173803/85/Cours-stat2-kharrat-30-320.jpg)
![3.3 Fonction génératrices des moments
MX (t) = E
¡
etX
¢
=
P
x∈X(Ω)
etx
P (X = x) =
∞P
x=0
etx
.
e−λ
.λx
x!
= e−λ
∞P
x=0
(λet
)
x
x!
= e−λ
eλet
= eλ(et
−1)
MX (t) = eλ(et
−1)
Déduction de l’espérance et de la variance à partir de la F.G.M :
∂MX (t)
∂t
= λet
eλ(et
−1) ⇒ E (X) =
∂MX (t)
∂t
¯
¯
¯
¯
t=0
= λ
∂2
MX (t)
∂t2
= λet
eλ(et
−1) + (λet
)
2
eλ(et
−1) = (λet
+ 1) λet
eλ(et
−1) ⇒ E
¡
X2
¢
=
∂2
MX (t)
∂t2
¯
¯
¯
¯
t=0
= λ2
+ λ
⇒ V (X) = E
¡
X2
¢
− [E (X)]2
= λ2
+ λ − λ2
= λ
3.4 Application
Une entreprise A a effectué une étude sur le nombre d’accidents de travail qui se sont produits durant les deux
dernières années. Ceci a permis d’établir que le taux moyen d’accidents de travail a été de 1, 6 accidents/jour.
En admettant que le nombre d’accidents de travail en une journée obéit à la loi de Poisson, quelle est la
probabilité d’observer plus de 2 accidents/jour ?
On a X : nombre d’accidents de travail par jour à P(1, 6)
P(X > 2) = 1 − P(X ≤ 2) = 1 − 0, 783 = 0, 217. (P(X ≤ 2) = 0, 783; voir table 4-1 : λ = 1, 6)
= 1 − P(X = 0) − P(X = 1) − P(X = 2)
= 1 − 0, 202 − 0, 323 − 0, 258 = 0, 217 (voir table 3-1)
3.5 Stabilité de la loi de Poisson par addition
Soient X1 et X2 deux variables aléatoires de Poisson de paramètres respectivement λ1 et λ2
c.-à-d. X1 Ã P(λ1) et X2 Ã P(λ2)
si X1 et X2 sont indépendantes alors la v.a. Y = X1 + X2 Ã P(λ1 + λ2).
En effet :
MY (t) = E
¡
etY
¢
= E
¡
et(X1+X2)
¢
= E
¡
etX1
.etX2
¢
= E
¡
etX1
).E(etX2
¢
[X1etX2 sont indépendantes]
= MX1 (t) .MX2 (t) = eλ1(et
−1).eλ2(et
−1) = e(λ1+λ2)[et
−1]
e(λ1+λ2)[et
−1] est la F.G.M. d’une variable de Poisson de paramètre (λ1 + λ2)
d’où Y = X1 + X2 Ã P(λ1 + λ2).
3.6 Approximation de la loi binomiale par la loi de Poisson
On utilisera, le plus souvent, la loi de Poisson comme approximation d’une loi binomiale.
Supposons que les conditions d’application de la loi binomiale sont réalisées mais que toutefois le nombre
d’épreuves (la taille d’échantillon n) est très grand, que p est faible, de telle façon que np reste petit par rapport à
n, alors on peut approximer la loi binomiale de paramètres (n, p) par une loi de Poisson de paramètre (λ = np) .
En pratique l’approximation est valable si :
n ≥ 30, p ≤ 0, 1.
Démonstration : (Facultative)
X Ã B (n, p) ⇒ MX(t) = [pet
+ (1 − p)]
n
Y Ã P(λ) ⇒ MY (t) = eλ(et
−1)
Posons λ = np
MX(t) = [pet
+ (1 − p)]
n
=
∙
1 +
1
n
(et
− 1)np
¸n
=
∙
1 +
λ(et
− 1)
n
¸n
lim
n→∞
MX(t) = lim
n→∞
∙
1 +
λ(et
− 1)
n
¸n
= eλ(et
−1)
= MY (t).
10](https://image.slidesharecdn.com/cours-stat2-kharrat-161102173803/85/Cours-stat2-kharrat-31-320.jpg)

![ce qui nous permet d’ecrire :
∞P
n=1
nqn−1
=
1
(1 − q)2 si |q| < 1 (A)
De même,
si |q| < 1, on a
∞P
n=0
qn
=
1
1 − q
⇒
µ ∞P
n=0
qn
¶00
=
µ
1
1 − q
¶00
=
2
(1 − q)3
or
∞P
n=0
qn
= 1 + q +
∞P
n=2
qn
⇒
µ ∞P
n=0
qn
¶00
=
µ
1 + q +
∞P
n=2
qn
¶00
=
µ ∞P
n=2
qn
¶00
=
∞P
n=2
(qn
)00
=
∞P
n=2
n (n − 1) qn−2
et on a
∞P
n=1
n (n − 1) qn−2
=
2
(1 − q)3 si |q| < 1 (B)
4.2.1 Espérance mathématique
E(X) =
P
x∈X(Ω)
x.P (X = x) =
∞P
x=1
x.p. (1 − p)
x−1
= p
∞P
x=1
x (1 − p)
x−1
or d’après (A), on a
∞P
x=1
x (1 − p)
x−1
=
1
(1 − (1 − p))
2 =
1
p2
⇒ E(X) =
1
p
4.2.2 Variance
V (X) = E
¡
X2
¢
− [E (X)]2
E
¡
X2
¢
=
P
x∈X(Ω)
x2
.P (X = x) =
∞P
x=1
x2
. (1 − p)
x−1
p =
∞P
x=1
(x (x − 1) + x) . (1 − p)
x−1
p
= p
∞P
x=1
x (x − 1) . (1 − p)
x−1
+
∞P
x=1
x (1 − p)
x−1
p
= p
∞P
x=1
x (x − 1) . (1 − p)
x−1
+ E(X)
= 0 + p (1 − p)
∞P
x=2
x (x − 1) . (1 − p)
x−2
+
1
p
or d’après (B), on a
∞P
x=2
x (x − 1) (1 − p)
x−2
=
2
(1 − (1 − p))
3 =
2
p3
.
⇒ E
¡
X2
¢
= p (1 − p)
2
p3
+
1
p
=
2 (1 − p) + p
p2
⇒ V (X) =
2 (1 − p) + p
p2
−
1
p2
=
(1 − p)
p2
=
q
p2
V (X) =
(1 − p)
p2
=
q
p2
4.3 Fonction génératrice des moments
MX(t) = E(etX
) =
∞P
x=1
etx
. (1 − p)
x−1
.p = pet
∞P
x=1
[et
(1 − p)]
x−1
= pet
∞P
y=0
(qet
)
y
avec (y = x − 1)
= pet 1
1 − qet
si qet
< 1
⇔ MX(t) =
pet
1 − qet
si t < Log
µ
1
q
¶
(on vérifie bien que t = 0 ∈
¸
−∞, Log
µ
1
q
¶∙
, puisque 0 < q < 1 ⇔
1
q
>
1 ⇔ Log
µ
1
q
¶
> 0).
On peut donc déduire l’espérance et la variance à partir de la fonction génératrice des moments (prenez le temps
de le faire !).
12](https://image.slidesharecdn.com/cours-stat2-kharrat-161102173803/85/Cours-stat2-kharrat-33-320.jpg)
![5 La loi binomiale négative d’ordre k : X Ã B (k, p)
On se place dans les conditions d’une loi géométrique, seulement on s’intéresse à présent à répéter l’épreuve
élémentaire jusqu’à l’obtention du ki`eme
"succès". Soit X la variable aléatoire définie par le nombre de répétitions
qu’il faut effectuer pour obtenir k succès. Pour obtenir k succès, on doit avoir recours à au moins k répétitions de
l’épreuve élémentaire. l’ensemble des observables de X est donc X (Ω) = {k, k + 1, . . .}
l’événement {X = x} se réalise si et seulement si :
— (k − 1) "succès" ont été obtenu, avant la répétition numéro x (c.-à-d. en (x − 1) répétitions)
— le ki`eme
"succès" a été obtenu à la répétition numéro x
et on peut écrire :
P(X = x) = P(d’avoir recours à x répétitions jusqu’à l’apparition du ki`eme
"succès")
= P(d’obtenir (k − 1) "succès" en (x − 1) répétitions) × P(d’obtenir "succès" à la x`eme
répétition)
= P(d’obtenir (k − 1) "succès" en (x − 1) répétitions) × p
= P(Y = k − 1) × p, avec Y Ã B (x − 1, p) , y ∈ {0, 1, . . . , x − 1}
= {k−1
x−1pk−1
(1 − p)
x−k
× p = {k−1
x−1pk
(1 − p)
x−k
5.1 Définition
On dit qu’une variable aléatoire X suit la loi binomiale négative d’ordre k et on note X Ã B (k, p), si sa loi de
probabilité est donnée par :
P (X = x) =
½
{k−1
x−1pk
(1 − p)x−k
∀ x ∈ {k, k + 1, . . .}
0 sinon
5.2 Paramètres descriptifs
5.2.1 Espérance mathématique
E(X) =
P
x∈X(Ω)
x.P (X = x) =
∞P
x=k
x.{k−1
x−1pk
(1 − p)x−k
=
∞P
x=k
x.
(x − 1)!
(x − k)! (k − 1)!
pk
(1 − p)
x−k
5. MY (t) = E(etY
) =
∞P
y=r
ety
.{r−1
y−1pr
(1 − p)y−r
= pr
∞P
y=r
etr
et(y−r)
.{r−1
y−1 (1 − p)y−r
= etr
pr
∞P
y=r
{r−1
y−1 [(1 − p) et
]
y−r
= etr
pr
[1 − (1 − p) et
]
−r
si (1 − p) et
< 1
=
∙
pet
1 − (1 − p) et
¸r
si t < Log
∙
1
(1 − p)
¸
∂MY (t)
∂t
= r
∙
pet
1 − (1 − p) et
¸r−1
"
pet
(1 − (1 − p) et
) + pet
((1 − p) et
)
(1 − (1 − p) et)2
#
E (X) =
∂MX (t)
∂t
¯
¯
¯
¯
t=0
= r
∙
p
p
¸r−1 ∙
p2
+ p − p2
p2
¸
=
r
p
.
13](https://image.slidesharecdn.com/cours-stat2-kharrat-161102173803/85/Cours-stat2-kharrat-34-320.jpg)
![Deuxième partie
Les lois continues
1 La loi uniforme continue (ou loi rectangulaire) : X Ã U ([a, b])
1.1 Définition
Soit X une variable aléatoire continue. Sa distribution est dite uniforme sur [a, b] (a < b), si sa densité de
probabilité est constante sur cet intervalle avec :
f(x) =
( 1
b − a
si x ∈ [a, b]
0 sinon
et on écrit X Ã U ([a, b])
• Graphiquement, on a l’allure suivante :
( )f x
1
b a−
a b
On vérifie que
R +∞
−∞
f(x)dx =
R b
a
1
b − a
dx =
1
b − a
[x]b
a =
b − a
b − a
= 1
• L’aire comprise entre la courbe de f(x) et l’axe des abscisses n’est autre que la surface du rectangle de base (a, b)
et de hauteur
1
b − a
, d’où l’appellation de loi rectangulaire.
• Soient c et d deux réel tels que a < c < d < b, alors P(c < X < d) =
R d
c
f(x)dx =
d − c
b − a
( )f x
1
b a−
a bc d
( )P c X d< <
1.2 Fonction de répartition
F : R −→ [0, 1]
x 7−→ F (x) = P (X < x) =
R x
−∞
f(t)dt
avec f(t) =
( 1
b − a
si t ∈ [a, b]
0 sinon
14](https://image.slidesharecdn.com/cours-stat2-kharrat-161102173803/85/Cours-stat2-kharrat-35-320.jpg)
![si x < a ⇒ F (x) =
R x
−∞
f(t)dt = 0
si a ≤ x ≤ b ⇒ F (x) =
R x
−∞
f(t)dt =
R a
−∞
f(t)dt +
R x
a
f(t)dt =
1
b − a
R x
a
dt =
x − a
b − a
si x > b ⇒ F (x) =
R x
−∞
f(t)dt =
R a
−∞
f(t)dt +
R b
a
f(t)dt +
R x
b
f(t)dt =
1
b − a
R b
a
dt = 1
⇒ F(x) =
0 si x < a
x − a
b − a
si a ≤ x ≤ b
1 si x > b
( )F x
2
a b+a b
1
0,5
• La médiane est la valeur de x telle que F(x) = 0, 5
F(x) = 0, 5 ⇒
x − a
b − a
= 0, 5 ⇒ x =
1
2
(b − a) + a =
a + b
2
⇒ Me =
a + b
2
1.3 Paramètres descriptifs
1.3.1 Espérance mathématique
E(X) =
R +∞
−∞
xf(x)dx =
1
b − a
R b
a
xdx =
1
b − a
·
x2
2
¸b
a
=
b2
− a2
2 (b − a)
=
a + b
2
E(X) =
a + b
2
1.3.2 Variance
V (X) = E(X2
) − [E(X)]
2
or E(X2
) =
R +∞
−∞
x2
f(x)dx =
1
b − a
R b
a
x2
dx =
1
b − a
·
x3
3
¸b
a
=
b3
− a3
3 (b − a)
=
(b − a)
¡
a2
+ b2
+ ab
¢
3 (b − a)
=
¡
a2
+ b2
+ ab
¢
3
⇒ V (X) =
¡
a2
+ b2
+ ab
¢
3
−
(a + b)
4
2
=
(b − a)2
12
V (X) =
(b − a)2
12
1.4 Fonction génératrice des moments
MX (t) = E
¡
etX
¢
=
R +∞
−∞
etx
f(x)dx =
1
b − a
R b
a
etx
dx =
1
b − a
·
etx
t
¸b
a
=
etb
− eta
t (b − a)
si t 6= 0
⇒ MX (t) =
etb
− eta
t (b − a)
si t 6= 0
1 sinon
• Déduction de l’espérance à partir de la fonction génératrice des moments (facultative) :
15](https://image.slidesharecdn.com/cours-stat2-kharrat-161102173803/85/Cours-stat2-kharrat-36-320.jpg)
![∂MX (t)
∂t
=
¡
betb
− aeta
¢
(t (b − a)) − (b − a)
¡
etb
− eta
¢
t2 (b − a)2
=
¡
betb
− aeta
¢
t (b − a)
−
¡
etb
− eta
¢
t2 (b − a)
on sait que eta
=
∞P
x=0
(ta)x
x!
= 1 + ta +
(ta)2
2!
+
∞P
x=3
(ta)x
x!
etb
=
∞P
x=0
(tb)
x
x!
= 1 + tb +
(tb)
2
2!
+
∞P
x=3
(tb)
x
x!
⇒ etb
− eta
= t (b − a) +
t2
¡
b2
− a2
¢
2
+
∞P
x=3
tx
(bx
− ax
)
x!
⇒
etb
− eta
t2 (b − a)
=
1
t
+
b + a
2
+
∞P
x=3
tx−2
(bx
− ax
)
(b − a) x!
de même, on a aeta
= a + ta2
+
∞P
x=2
tx
ax+1
x!
betb
= b + tb2
+
∞P
x=2
tx
bx+1
x!
⇒ betb
− aeta
= (b − a) + t
¡
b2
− a2
¢
+
∞P
x=2
tx
¡
bx+1
− ax+1
¢
x!
⇒
betb
− aeta
t (b − a)
=
1
t
+ (b + a) +
∞P
x=2
tx−1
¡
bx+1
− ax+1
¢
(b − a) x!
⇒
∂MX (t)
∂t
=
¡
betb
− aeta
¢
t (b − a)
−
¡
etb
− eta
¢
t2 (b − a)
=
(b + a)
2
+
∞P
x=2
tx−1
¡
bx+1
− ax+1
¢
(b − a) x!
−
∞P
x=3
tx−2
(bx
− ax
)
(b − a) x!
⇒ E(X) = lim
t→0
∂MX (t)
∂t
=
(b + a)
2
2 La loi exponentielle : X Ã ξ (θ)
2.1 Définition
On dit qu’une variable aléatoire X suit une loi exponentielle de paramètre θ > 0, lorsque sa densité de probabilité
est définie par :
f(x) =
½
θe−θx
si x ≥ 0
0 sinon
et on note X Ã ξ (θ)
On vérifie que
R +∞
−∞
f(x)dx =
R +∞
0
θe−θx
dx =
£
−e−θx
¤+∞
0
= 1.
2.2 Fonction de répartition
F : R −→ [0, 1]
x 7−→ F (x) = P (X < x) =
R x
−∞
f(t)dt avec f(t) =
½
θe−θt
si t ≥ 0
0 sinon
si x < 0 ⇒ F (x) =
R x
−∞
f(t)dt = 0
si x ≥ 0 ⇒ F (x) =
R x
−∞
f(t)dt =
R x
0
θe−θt
dt =
£
−e−θt
¤x
0
= 1 − e−θx
⇒ F(x) =
½
0 si x < 0
1 − e−θx
si x ≥ 0
On vérifie que lim
x→+∞
F(x) = lim
x→+∞
¡
1 − e−θx
¢
= 1
• La médiane est telle que F(Me) = 0, 5
F(Me) = 0, 5 ⇔ 1 − e−θMe
= 0, 5 ⇔ e−θMe
= 0, 5 ⇔ Me = −
1
θ
Log (0, 5)
16](https://image.slidesharecdn.com/cours-stat2-kharrat-161102173803/85/Cours-stat2-kharrat-37-320.jpg)
![2.3 Paramètres descriptifs
2.3.1 Espérance mathématique
E(X) =
R +∞
−∞
xf(x)dx =
R +∞
0
xθe−θx
dx
en intégrant par partie : u(x) = x ⇒ u0
(x) = 1
v0
(x) = θe−θx
⇒ v(x) = −e−θx
⇒ E(X) =
R +∞
0
xθe−θx
dx =
£
−xe−θx
¤+∞
0
+
R +∞
0
e−θx
dx =
·
−
1
θ
e−θx
¸+∞
0
=
1
θ
E(X) =
1
θ
2.3.2 Variance
V (X) = E(X2
) − [E(X)]
2
avec E(X2
) =
R +∞
−∞
x2
f(x)dx =
R +∞
0
x2
θe−θx
dx
en intégrant par partie : u(x) = x2
⇒ u0
(x) = 2x
v0
(x) = θe−θx
⇒ v(x) = −e−θx
⇒ E(X2
) =
R +∞
0
x2
θe−θx
dx =
£
−x2
e−θx
¤+∞
0
+ 2
R +∞
0
xe−θx
dx =
2
θ
R +∞
0
xθe−θx
dx =
2
θ
E(X) =
2
θ2
⇒ V (X) =
2
θ2 −
1
θ2 =
1
θ2
V (X) =
1
θ2
Remarque :
Le moment non centré d’ordre k est défini par :
E(Xk
) =
R +∞
−∞
xk
f(x)dx =
R +∞
0
xk
θe−θx
dx = θ
R +∞
0
xk
e−θx
dx = θIk
en intégrant par partie : u(x) = xk
⇒ u0
(x) = kxk−1
v0
(x) = e−θx
⇒ v(x) = −
1
θ
e−θx
⇒ Ik =
·
−
xk
θ
e−θx
¸+∞
0
+
k
θ
R +∞
0
xk−1
e−θx
dx =
k
θ
Ik−1 ⇒ Ik =
k
θ
Ik−1 ∀k ∈ N∗
⇒
I1 =
1
θ
I0
I2 =
2
θ
I1
...
Ik−1 =
k − 1
θ
Ik−2
Ik =
k
θ
Ik−1
⇒ Ik =
k
θ
×
k − 1
θ
×· · ·
2
θ
×
1
θ
×I0 =
k!
θk
I0 avec I0 =
R +∞
0
e−θx
dx =
·
−
1
θ
e−θx
¸+∞
0
=
1
θ
⇒ Ik =
k!
θk
I0 =
k!
θk+1
⇒ E(Xk
) = θIk =
k!
θk
Implication : pour k = 1 on a E(X) =
1
θ
pour k = 2 on a E(X2
) =
2
θ2
2.4 Fonction génératrice des moments
MX (t) = E
¡
etX
¢
=
R +∞
−∞
etx
f(x)dx =
R +∞
0
etx
θe−θx
dx = θ
R +∞
0
e(t−θ)x
dx = θ
·
1
t − θ
e(t−θ)x
¸+∞
0
=
θ
θ − t
si
t < θ
Déduction de l’espérance et de la variance à partir de la F.G.M :
•
∂MX (t)
∂t
=
θ
(θ − t)
2 ⇒ E (X) =
∂MX (t)
∂t
¯
¯
¯
¯
t=0
=
1
θ
17](https://image.slidesharecdn.com/cours-stat2-kharrat-161102173803/85/Cours-stat2-kharrat-38-320.jpg)
![•
∂2
MX (t)
∂t2
=
2θ
(θ − t)3 ⇒ E
¡
X2
¢
=
∂2
MX (t)
∂t2
¯
¯
¯
¯
t=0
=
2
θ2 ⇒ V (X) = E(X2
) − [E(X)]2
=
1
θ2
Remarque : La loi exponentielle n’est pas stable par l’addition
Soient X1 et X2 deux variables aléatoires indépendantes telles que : X1 Ã ξ (θ1) et X2 Ã ξ (θ2)
si Y = X1 + X2, nous n’avons pas Y Ã ξ (θ1 + θ2) c.-à-d. nous n’avons pas MY (t) =
(θ1 + θ2)
(θ1 + θ2) − t
MY (t) = E
¡
etY
¢
= E
¡
et(X1+X2)
¢
= E
¡
etX1
¢
E
¡
etX2
¢
= MX1 (t) MX2 (t) =
θ1
θ1 − t
×
θ2
θ2 − t
=
θ1θ2
(θ1 − t) (θ2 − t)
2.5 Application
Soient X et Y deux variables aléatoires tells que X Ã U ([−3, −1]) et Y Ã ξ (θ) .
Trouver θ, sachant que V (X) = V (Y ).
Solution :
X Ã U ([−3, −1]) ⇒ V (X) =
(−1 + 3)2
12
=
1
3
Y Ã ξ (θ) ⇒ V (Y ) =
1
θ2
V (X) = V (Y ) ⇔
1
θ2 =
1
3
⇔ θ2
= 3 ⇔ |θ| =
√
3 ⇒ θ =
√
3 (θ = −
√
3 est à rejeter car θ > 0 par hypothèse).
3 La loi gamma : X Ã γ (α, θ)
3.1 La fonction Gamma
3.1.1 Définition
La fonction Gamma est définie sur R∗
+ et à valeurs dans R+ par :
Γ (α) =
Z +∞
0
tα−1
e−t
dt
3.1.2 Propriétés de la fonction Gamma
1. ∀α ∈ R∗
+ on a Γ (α + 1) = αΓ (α) .
En effet, Γ (α + 1) =
R +∞
0
tα
e−t
dt
en intégrant par partie : u(t) = tα
⇒ u0
(t) = αtα−1
v0
(x) = e−t
⇒ v(x) = −e−t
on obtient : Γ (α + 1) =
R +∞
0
tα
e−t
dt = [−tα
e−t
]
+∞
0 +
R +∞
0
αtα−1
e−t
dt
= α
R +∞
0
tα−1
e−t
dt = αΓ (α)
Implication : ∀n ∈ N∗
Γ (n) = (n − 1)!
∀α ∈ R∗
+ on a Γ (α + 1) = αΓ (α)
pour α = 1 ⇒ Γ (2) = 1 × Γ (1)
pour α = 2 ⇒ Γ (3) = 2 × Γ (2) = 2 × 1 × Γ (1)
...
pour α = n − 1 ⇒ Γ (n) = (n − 1) × Γ (n − 1) = (n − 1) × (n − 2) × · · · × 2 × 1 × Γ (1)
= (n − 1)! × Γ (1)
or Γ (1) =
R +∞
0
e−t
dt = [−e−t
]
+∞
0 = 1 (e−t
n’est autre que la densité d’une ξ (1))
∀n ∈ N∗
Γ (n) = (n − 1)!
2. Γ
µ
1
2
¶
=
R +∞
0
t
−1
2 e−t
dt =
√
Π
Démonstration (facultative)
On sait que Γ (α) =
R +∞
0
tα−1
e−t
dt. En posant x =
√
t ⇒ x2
= t ⇒ dt = 2xdx, on a :
18](https://image.slidesharecdn.com/cours-stat2-kharrat-161102173803/85/Cours-stat2-kharrat-39-320.jpg)

![3.2.2 Paramètres descriptifs
Espérance mathématique
E(X) =
R +∞
−∞
xf(x)dx =
R +∞
0
x
θα
Γ (α)
xα−1
e−θx
dx =
θα
Γ (α)
R +∞
0
xα
e−θx
dx =
θα
Γ (α)
Γ (α + 1)
θα+1 =
α
θ
E(X) =
α
θ
Variance
V (X) = E(X2
) − [E(X)]
2
E(X2
) =
R +∞
−∞
x2
f(x)dx =
R +∞
0
x2 θα
Γ (α)
xα−1
e−θx
dx =
θα
Γ (α)
R +∞
0
xα+1
e−θx
dx =
θα
Γ (α)
Γ (α + 2)
θα+2
=
θα
Γ (α)
α (α + 1) Γ (α)
θα+2
=
α (α + 1)
θ2
V (X) =
α (α + 1)
θ2 −
³α
θ
´2
=
α
θ2
V (X) =
α
θ2
3.2.3 Fonction génératrice des moments
MX (t) = E
¡
etX
¢
=
R +∞
−∞
etx
f(x)dx =
R +∞
0
etx θα
Γ (α)
xα−1
e−θx
dx
=
θα
Γ (α)
R +∞
0
xα−1
e(t−θ)x
dx
=
θα
Γ (α)
R +∞
0
xα−1
e−(θ−t)x
dx
=
θα
Γ (α)
Γ (α)
(θ − t)α =
·
θ
(θ − t)
¸α
avec θ > t
Remarque : pour α = 1, on retrouve la fonction génératrice des moments d’une loi exponentielle ξ (θ).
Déduction de l’espérance et de la variance à partir de la fonction génératrice des moments :
On a : MX (t) =
·
θ
(θ − t)
¸α
•
∂MX (t)
∂t
= α
θ
(θ − t)2
·
θ
(θ − t)
¸α−1
= α
θα
(θ − t)α+1 ⇒ E (X) =
∂MX (t)
∂t
¯
¯
¯
¯
t=0
=
α
θ
•
∂2
MX (t)
∂t2
=
"
α
θα
(θ − t)
α+1
#0
= αθα
h
(θ − t)
−α−1
i0
= αθα
h
(−α − 1) (−1) (θ − t)
−α−2
i
= α (α + 1)
"
θα
(θ − t)α+2
#
⇒ E
¡
X2
¢
=
∂2
MX (t)
∂t2
¯
¯
¯
¯
t=0
=
α (α + 1)
θ2 =
α2
θ2 +
α
θ2 ⇒ V (X) = E(X2
) − [E(X)]2
=
α
θ2
3.2.4 Stabilité de la loi gamma par l’addition
Soient X1 et X2 deux variables aléatoires indépendantes telles que X1 Ã γ (α1, θ) et X2 Ã γ (α2, θ), alors la
variable aléatoire Y = X1 + X2 Ã γ (α1 + α2, θ) :
MY (t) = E
¡
etY
¢
= E
¡
et(X1+X2)
¢
= E
¡
etX1
¢
E
¡
etX2
¢
= MX1 (t) MX2 (t) =
·
θ
(θ − t)
¸α1
×
·
θ
(θ − t)
¸α2
=
·
θ
(θ − t)
¸α1+α2
c’est la fonction génératrice des moments d’une γ (α1 + α2, θ)
20](https://image.slidesharecdn.com/cours-stat2-kharrat-161102173803/85/Cours-stat2-kharrat-41-320.jpg)

![4.2.2 Variance
1`ere
méthode :
V (X) = E(X − E(X))2
= E(X − m)2
=
1
σ
√
2Π
Z +∞
−∞
(x − m)2
e
−
1
2
x − m
σ
2
dx, posons t =
x − m
σ
⇒
½
x = σt + m
dx = σdt
=
σ2
√
2Π
Z +∞
−∞
t2
e
−
t2
2 dt
en intégrant par partie : u(t) = t ⇒ u0
(t) = 1
v0
(x) = te
−
t2
2 ⇒ v(x) = −e
−
t2
2
⇒ V (X) =
σ2
√
2Π
−te
−
t2
2
+∞
−∞
+
Z +∞
−∞
e
−
t2
2 dt
=
σ2
√
2Π
h
0 +
√
2Π
i
= σ2
V (X) = σ2
2`eme
méthode :
V (X) = E(X2
) − [E(X)]
2
avec E(X) = m
E(X2
) =
R +∞
−∞
x2
f(x)dx =
1
σ
√
2Π
Z +∞
−∞
x2
e
−
1
2
x − m
σ
2
dx , posons t =
x − m
σ
⇒
½
x = σt + m
dx = σdt
=
1
√
2Π
Z +∞
−∞
(σt + m)
2
e
−
t2
2 dt
=
1
√
2Π
Z +∞
−∞
³
(σt)2
+ 2mσt + m2
´
e
−
t2
2 dt
=
1
√
2Π
σ2
Z +∞
−∞
t2
e
−
t2
2 dt + 2mσ
Z +∞
−∞
te
−
t2
2 dt + m2
Z +∞
−∞
e
−
t2
2 dt
=
1
√
2Π
σ2
−te
−
t2
2
+∞
−∞
+
Z +∞
−∞
e
−
t2
2 dt
+ 2mσ
−e
−
t2
2
+∞
−∞
+ m2
√
2Π
=
1
√
2Π
h
σ2
√
2Π + m2
√
2Π
i
⇒ E(X2
) = σ2
+ m2
⇒ V (X) = E(X2
) − [E(X)]2
= σ2
+ m2
− m2
= σ2
4.3 Représentation graphique
f(x)
xm
1
2σ Π
m α− m α+
( ) ( )f m f mα α− = +
x m= est un axe de sym étrie
( )Mo Me E X m= = =
22](https://image.slidesharecdn.com/cours-stat2-kharrat-161102173803/85/Cours-stat2-kharrat-43-320.jpg)
![4.4 Fonction de répartition
F : R −→ [0, 1]
x 7−→ F (x) = P (X < x) =
R x
−∞
f(t)dt =
1
σ
√
2Π
Z x
−∞
e
−
1
2
t − m
σ
2
dt
On vérifie que lim
x→−∞
F(x) = 0 et lim
x→+∞
F(x) =
1
σ
√
2Π
lim
x→+∞
Z x
−∞
e
−
1
2
t − m
σ
2
dt , posons z =
t − m
σ
=
1
√
2Π
lim
x→+∞
Z x−m
σ
−∞
e
−
z2
2 dz = 1
On vérifie aussi que m est la médiane :
F (m) =
1
σ
√
2Π
Z m
−∞
e
−
1
2
t − m
σ
2
dt, posons z =
t − m
σ
⇒
½
dt = σdz
lorsque t → m on a z → 0
=
1
√
2Π
Z 0
−∞
e
−
z2
2 dz =
1
√
2Π
1
2
Z +∞
−∞
e
−
z2
2 dz
=
1
2
Graphiquement, on a l’allure suivante :
1
( )F x
xo m
0, 5
4.5 Fonction génératrice des moments
MX(t) = E(etX
) =
R +∞
−∞
etx
f(x)dx =
1
σ
√
2Π
Z +∞
−∞
etx
e
−
1
2
x − m
σ
2
dx , posons z =
x − m
σ
⇒
½
x = σz + m
dx = σdz
=
1
√
2Π
Z +∞
−∞
et(σz+m)
e− z2
2 dz
=
etm
√
2Π
Z +∞
−∞
etσz− z2
2 dz
=
etm
√
2Π
Z +∞
−∞
e− 1
2 (z2
−2tσz+(σt)2
−(σt)2
)dz
=
etm
√
2Π
Z +∞
−∞
e− 1
2 (z−tσ)2
e
(σt)2
2 dz, posons u = z − tσ ⇒ du = dz
=
etm
.e
(σt)2
2
√
2Π
Z +∞
−∞
e− u2
2 du
| {z }
√
2Π
MX(t) = etm+ σ2t2
2 ∀t ∈ R
Déduction de l’espérance et de la variance à partir de la F.G.M :
•
∂MX (t)
∂t
=
¡
m + σ2
t
¢
etm+ σ2t2
2 ⇒ E (X) =
∂MX (t)
∂t
¯
¯
¯
¯
t=0
= m
23](https://image.slidesharecdn.com/cours-stat2-kharrat-161102173803/85/Cours-stat2-kharrat-44-320.jpg)
![•
∂2
MX (t)
∂t2
= σ2
etm+ σ2t2
2 +
¡
m + σ2
t
¢2
etm+ σ2t2
2 ⇒ E
¡
X2
¢
=
∂2
MX (t)
∂t2
¯
¯
¯
¯
t=0
= σ2
+ m2
⇒ V (X) = E(X2
) − [E(X)]
2
= σ2
Exemple :
Si X admet la F.G.M. suivante : MX(t) = e(100t+50t2
) ∀t ∈ R, déterminer E(X) et V (X).
MX(t) = e(100t+50t2
) = e(100t+ 100
2 t2
) = e
100t+ 102
2 t2
qui est la F.G.M. d’une variable aléatoire X Ã N (100, 100)
et on a E(X) = V (X) = 100
4.6 Stabilité de la loi normale par l’addition
Soient X1 et X2 deux variables aléatoires indépendantes telles que X1 Ã N
¡
m1, σ2
1
¢
et X2 Ã N
¡
m2, σ2
2
¢
, alors
la variable aléatoire Y = X1 + X2 Ã N
¡
m1 + m2, σ2
1 + σ2
2
¢
preuve :
X1 Ã N
¡
m1, σ2
1
¢
⇒ MX1
(t) = etm1+
σ2
1t2
2
X2 Ã N
¡
m2, σ2
2
¢
⇒ MX2 (t) = etm2+
σ2
2t2
2
MY (t) = E
¡
etY
¢
= E
¡
et(X1+X2)
¢
= E
¡
etX1
¢
E
¡
etX2
¢
= MX1
(t) MX2
(t) = etm1+
σ2
1t2
2 × etm2+
σ2
2t2
2
= et(m1+m2)+
(σ2
1+σ2
2)t2
2
c’est la fonction génératrice des moments d’une N
¡
m1 + m2, σ2
1 + σ2
2
¢
. La loi normale est stable par l’addition.
4.7 La loi normale centrée réduite (ou standard) : Z Ã N (0, 1)
4.7.1 Définition
Soit Z une variable aléatoire continue. On dit que Z est une variable aléatoire normale centrée réduite si sa
densité de probabilité est définie par :
fZ(z) =
1
√
2Π
e
−
z2
2 ∀z ∈ R
et on note Z Ã N (0, 1)
4.7.2 Théorème
Si X est une variable aléatoire qui quit la loi normale de paramètres
¡
m, σ2
¢ £
X Ã N
¡
m, σ2
¢¤
, alors la variable
aléatoire Z définie par Z =
X − m
σ
suit la loi normale de paramètres (0, 1)
X Ã N
¡
m, σ2
¢
⇒ Z =
X − m
σ
à N (0, 1)
preuve :
X Ã N
¡
m, σ2
¢
⇒ MX(t) = etm+ σ2t2
2
Soit Z =
X − m
σ
⇒ MZ(t) = E(etZ
) = E(et(X−m
σ )) = E(e
−tm
σ e
tX
σ ) = e
−tm
σ E(e
tX
σ )
= e
−tm
σ MX( t
σ )
= e
−tm
σ e
tm
σ + t2
2
= e
t2
2 = e0t+ (1)2t2
2
qui est la F.G.M. d’une normale de paramètre (m = 0, σ2
= 1), donc Z =
X − m
σ
à N (0, 1)
conséquence :
La conséquence importante de ce théorème est que, par ce changement de variable, n’importe quelle loi normale
peut être ramenée à la seule loi N (0, 1)
Remarque : Si X Ã N (0, 1) alors Y = X2
à γ
µ
1
2
,
1
2
¶
On a X Ã N (0, 1) ⇒ X (Ω) = R et Y = X2
⇒ Y (Ω) = R+
24](https://image.slidesharecdn.com/cours-stat2-kharrat-161102173803/85/Cours-stat2-kharrat-45-320.jpg)
![∀y ∈ R+ on a FY (y) = P(Y < y) = P(X2
< y) = P(−
√
y < X <
√
y) = FX(
√
y) − FX(−
√
y)
⇒ ∀y ∈ R∗
+ on a fY (y) = F0
Y (y) =
1
2
√
y
fX(
√
y) +
1
2
√
y
fX(−
√
y)
=
1
2
√
y
1
√
2Π
e− y
2 +
1
2
√
y
1
√
2Π
e− y
2
=
y− 1
2
√
2Π
e− y
2 =
¡1
2
¢1
2
√
Π
y
1
2 −1
e− 1
2 y
¡1
2
¢1
2
√
Π
y
1
2 −1
e− 1
2 y
est de la forme
θα
Γ (α)
yα−1
e−θy
avec θ =
1
2
; α =
1
2
et Γ
µ
1
2
¶
=
√
Π ⇒ Y = X2
à γ
µ
1
2
,
1
2
¶
.
4.7.3 Fonction de répartition de la loi normale centrée réduite
F : R −→ [0, 1]
z 7−→ FZ (z) = P (Z < z) =
R z
−∞
f(t)dt =
1
√
2Π
Z z
−∞
e
−
t2
2 dt
1
ZF
zo
0, 5
f(z)
zz
( )
ZF z
( )
2
21
2
tz
ZF z e dt−
Π−∞
= ∫
z
FZ (z) peut être lue directement dans la table 5-1
exemple : FZ (2, 07) = 0, 981 (intersection de la ligne (2) avec la colonne (0, 07))
cette table donne uniquement la valeur de FZ pour des valeurs de z positifs.
Propriétés
1. Le graphe de fZ est symétrique par rapport à l’axe des ordonnées (fZ(z) =
1
√
2Π
e
−
z2
2 est une fonction
paire : ∀z ∈ R fZ(z) = fZ(−z))
f(z)
zz-z
( )Z zF −
FZ (−z) = P(Z < −z) = P(Z > z) = 1 − P(Z < z)
= 1 − FZ (z)
FZ (−z) = 1 − FZ (z)
Exemple : FZ (−2, 07) = 1 − FZ (2, 07) = 0, 019
25](https://image.slidesharecdn.com/cours-stat2-kharrat-161102173803/85/Cours-stat2-kharrat-46-320.jpg)
![2. P (|Z| < z) = P(−z < Z < z) = P(Z < z) − P(Z < −z)
= FZ (z) − FZ (−z)
= FZ (z) − [1 − FZ (z)] = 2FZ (z) − 1 (c’est aussi égal à 1 − 2FZ (−z))
f(z)
zz-z
( )P Z z<
3. P (|Z| > z) = 1 − P (|Z| < z) = 1 − [2FZ (z) − 1]
= 2 [1 − FZ (z)]
= 2FZ (−z)
f(z)
zz-z
( )P Z z>
Application :
Soit Z Ã N (0, 1)
Calculer P(Z < −1, 37) ; P (|Z| < 1, 37) et P (|Z| > 1, 37)
• P(Z < −1, 37) = P(Z > 1, 37) = 1 − P(Z < 1, 37) = 1 − FZ (1, 37) = 1 − 0, 915 = 0, 085
La variable aléatoire normale centrée réduite a 8,5% de chances de prendre une valeur inférieure à -1,37 (ou
supérieure à 1,37)
• P (|Z| < 1, 37) = 1 − 2FZ (−1, 37) = 0, 83
• P (|Z| > 1, 37) = 2FZ (−1, 37) = 0, 17
4.8 Calcul des probabilités pour une loi normale quelconque
Par le changement de variable Z =
X − m
σ
, toutes les distributions normales se ramènent à celle de la variable
normale centrée réduite Z Ã N (0, 1) pour laquelle on dispose de la table de la fonction de répartition (table 5-1).
Soit X Ã N
¡
m, σ2
¢
si a et b sont deux réels quelconques (a < b), comment calculer P (X ∈ [a, b]) ?
P (X ∈ [a, b]) = P (a < X < b) =
Z b
a
1
σ
√
2Π
e
−
(x − m)
2
2σ2
dx, posons z =
x − m
σ
⇒
½
x = σz + m
dx = σdz
=
Z b−m
σ
a−m
σ
1
√
2Π
e
−
z2
2 dz
On reconnaît sous le signe intégrale la d.d.p. d’une variable aléatoire Z Ã N (0, 1)
⇒ P (a < X < b) =
Z b−m
σ
a−m
σ
1
√
2Π
e
−
z2
2 dz = P
µ
a − m
σ
< Z <
b − m
σ
¶
avec Z =
X − m
σ
à N (0, 1)
Conclusion :
Si X Ã N
¡
m, σ2
¢
et si a et b sont deux réels quelconques (a < b), alors on a
P (a < X < b) = P
µ
a − m
σ
< Z =
X − m
σ
<
b − m
σ
¶
avec Z =
X − m
σ
à N (0, 1)
26](https://image.slidesharecdn.com/cours-stat2-kharrat-161102173803/85/Cours-stat2-kharrat-47-320.jpg)
![Cette relation permet de ramener tout calcul de probabilité concernant une loi N
¡
m, σ2
¢
à un calcul de proba-
bilité concernant une loi N (0, 1) pour laquelle on dispose de la table des probabilités cumulées.
Exemple :
Soit X Ã N (2, 4)
Calculer P(3 ≤ X < 4) ; P(0 ≤ X ≤ 1) ; P(0 ≤ X ≤ 3) et P(−0, 4 < X < 4, 4)
• P(3 ≤ X < 4) = P(
3 − 2
2
≤
X − 2
2
<
4 − 2
2
) = P(
1
2
≤ Z < 1)
= P(Z < 1) − P(Z <
1
2
)
= FZ (1) − FZ (0, 5)
= 0, 841 − 0, 691 = 0, 15
f(z)
z10,5
avec Z Ã N (0, 1)
• P(0 ≤ X ≤ 1) = P(
0 − 2
2
≤
X − 2
2
≤
1 − 2
2
) = P(−1 ≤ Z ≤ −
1
2
)
= P(Z ≤ −
1
2
) − P(Z < −1)
= 1 − P(Z <
1
2
) − 1 + P(Z < 1)
= P(Z < 1) − P(Z <
1
2
) = P(
1
2
< Z < 1) = 0, 15
• P(0 < X ≤ 3) = P(
0 − 2
2
<
X − 2
2
≤
3 − 2
2
) = P(−1 < Z ≤
1
2
)
= P(Z ≤
1
2
) − P(Z ≤ −1)
= P(Z ≤
1
2
) − 1 + P(Z ≤ 1)
= FZ
µ
1
2
¶
+ FZ (1) − 1 = 0, 691 + 0, 841 − 1 = 0, 532
4.9 Détermination de la valeur de la variable normale pour une aire donnée
4.9.1 Définition
Soit X une variable aléatoire continue de fonction densité fX et de fonction de répartition FX. On appelle
quantile d’ordre α de X (α ∈ ]0, 1[) , qu’on note Xα, la valeur de la variable aléatoire X telle que :
FX(Xα) = P(X < Xα) =
Z Xα
−∞
fX(x)dx = α
X
( )X
f x
Xα
( ) ( )
( )
X
X
X
F X P X X
f x dx
α
α α
α
−∞
= <
= =∫
27](https://image.slidesharecdn.com/cours-stat2-kharrat-161102173803/85/Cours-stat2-kharrat-48-320.jpg)
![Exemples :
1. Soit Z Ã N (0, 1), déterminer Zα telle que α = 0, 949.
FZ(Zα) = P(Z < Zα) =
R Zα
−∞
fZ(z)dz = α = 0, 949
A partir de la table 5-2 qui donne la valeur Zα pour une aire α donnée, on a
X
( )Z
f z
0,949
1, 635z =
0,949Z=
α
0, 94
0, 009
1, 635
0, 50
0
0,949α =
0
2. Soit X Ã N (5, 4), déterminer Xα telle que α = 0, 84
FX(X0,84) = P(X < X0,84) = 0, 84, posons Z =
X − m
σ
=
X − 5
2
⇒ FX(X0,84) = P(X < X0,84) = P(
X − 5
2
<
X0,84 − 5
2
) = P(Z < Z0,84 =
X0,84 − 5
2
) = 0, 84 avec
Z Ã N (0, 1)
⇒ Z0,84 =
X0,84 − 5
2
= 0, 994 ⇒ X0,84 = 2Z0,84 + 5 = 6, 988
Ainsi, le quantile d’ordre α d’une variable aléatoire X Ã N
¡
m, σ2
¢
s’obtient à partir du quantile de même
ordre α de la loi normale centrée réduite :
si X Ã N
¡
m, σ2
¢
⇒ Xα = σZα + m où Zα est le quantile d’ordre α de Z Ã N (0, 1)
4.9.2 Propriété remarquable
Si α est un niveau de probabilité et Z Ã N (0, 1), alors il existe une valeur z = Z1− α
2
, appelée quantile d’ordre
1 − α
2 de Z qui vérifie :
P(−z < Z < z) = 1 − α
En effet, P(−z < Z < z) = P(Z < z) − P(Z < −z) = P(Z < z) − [1 − P(Z < z)]
= 2P(Z < z) − 1
on a donc P(−z < Z < z) = 1 − α ⇔ 2P(Z < z) − 1 = 1 − α
⇔ 2P(Z < z) = 2 − α
⇔ P(Z < z) = 1 −
α
2
⇔ z = Z1− α
2
f(z)
z
1 α−
2
α
2
α
2
z Zα− =
1 2
z Z α=
−
21Z α= − −
La relation non centrée correspondante est :
P(m − σZ1− α
2
< X = σZ + m < m + σZ1− α
2
) = 1 − α
28](https://image.slidesharecdn.com/cours-stat2-kharrat-161102173803/85/Cours-stat2-kharrat-49-320.jpg)
![Exemple :
Soit Z Ã N (0, 1), déterminer z telle que P(−z < Z < z) = 0, 95.
1 − α = 0, 95 ⇒ α = 0, 05 ⇒
α
2
= 0, 025 ⇒ 1 −
α
2
= 0, 975 ⇒ z = Z1− α
2
= z0,975 = 1, 96. Ceci signifie que 95%
des valeurs de Z sont comprises entre [−1, 96; 1, 96]
Si X Ã N
¡
m, σ2
¢
⇒ 95% des valeurs de X sont comprises entre [m − 1, 96σ; m + 1, 96σ] .
4.10 La loi normale en tant que loi limite
La loi normale ou loi de Laplace-Gauss est une distribution que l’on rencontre souvent en pratique. C’est la
loi qui s’applique à une variable statistique qui est la résultante d’un grand nombre de causes indépendantes, dont
les effets s’additionnent et dont aucune n’est prépondérante. [exemple : les erreurs de mesures : omissions, faute
d’information, erreur de saisie,....].
De plus, la loi normale présente la particularité d’être une loi limite vers laquelle tendent d’autres lois.
4.10.1 Théorème centrale limite (TCL)
Si X1, X2, . . . , Xn, n variables aléatoires indépendantes et identiquement distribuées (iid) selon une même loi
quelconque d’espérance m et de variance σ2
, alors, dès que n est grand (en pratique n ≥ 30), la variable aléatoire
Y =
Pn
i=1 Xi converge vers la loi normale d’espérance mY et de variance σ2
Y avec :
mY = E(Y ) = E (
Pn
i=1 Xi) =
Pn
i=1 E(Xi) = n.m et
σ2
Y = V (Y ) = V (
Pn
i=1) =
Pn
i=1 V (Xi) = n.σ2
.
si Xi à iid(m, σ2
) i : 1 . . . n alors, si n est grand (n ≥ 30), Y =
Pn
i=1 Xi à N
¡
nm, nσ2
¢
Implication : Y =
Pn
i=1 Xi à N
¡
nm, nσ2
¢
⇒
Y − nm
√
nσ
à N (0, 1) ⇔
X − m
σ√
n
à N (0, 1)
4.10.2 Approximation d’une loi binomiale ou d’une loi de Poisson par une loi normale
a/ Approximation de la loi binomiale par la loi normale
Soit une variable aléatoire X Ã B (n, p) . Si n ≥ 30 et 0, 4 ≤ p ≤ 0, 6 alors on peut approximer cette loi B (n, p)
par une loi normale N (np, npq)
si n ≥ 30 et 0, 4 ≤ p ≤ 0, 6 alors B (n, p) ≈ N (np, npq)
b/ Approximation de la loi de Poisson par la loi normale
Soit une variable aléatoire X Ã P (λ) . Si λ ≥ 20 alors on peut approximer cette loi P (λ) par une loi normale
N (λ, λ)
si λ ≥ 20 alors P (λ) ≈ N (λ, λ)
c/ Correction de continuité
L’approximation d’une loi discrète par une loi continue pose un problème puisque cette dernière affecte une valeur
nulle à la probabilité en un point P(X = x). Pour contourner cette difficulté, on procède à une correction dite de
"continuité" de la façon suivante :
P(X = x) = P(x − 0, 5 < X < x + 0, 5)
Exemple :
Soit X une variable aléatoire qui suit la loi P (25) . On a λ = 25 > 20 ⇒ P (25) ≈ N (25, 25) .
En utilisant la loi exacte de X, on peut calculer P(X = 18) =
e−25
(25)18
18!
= 0, 031.
En utilisant la loi normale, on a P(X = 18) = P(18 − 0, 5 < X < 18 + 0, 5) avec X
≈
à N (25, 25)
= P(
18 − 0, 5 − 25
5
<
X − 25
5
<
18 + 0, 5 − 25
5
)
= P(−1, 5 < Z < −1, 3) avec Z Ã N (0, 1)
= P(1, 3 < Z < 1, 5)
= FZ(1, 5) − FZ(1, 3)
= 0, 933 − 0, 903 = 0, 030
29](https://image.slidesharecdn.com/cours-stat2-kharrat-161102173803/85/Cours-stat2-kharrat-50-320.jpg)

![1.4 Lecture de la table de la loi de khi-deux
La loi de khi-deux n’est pas symétrique, la courbe de la densité de probabilité d’une variable aléatoire X qui
suit une loi de khi-deux est asymétrique étalée à droite.
2
αχ
2
( )P X αχ α< = 2
( ) 1P X αχ α> = −
x
f(x)
La table de la loi de khi-deux donne pour différentes valeurs de degrés de liberté (n), la valeur de χ2
α telle que
P(X < χ2
α) = α.
Exemple : Si X Ã χ2
(4). Déterminer χ2
α telle que α = 0, 8.
/n α
1
0, 005
2
3
4
0, 80
30
0, 995
5, 989
2
αχ
⎫⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎬
⎪⎪⎪⎪⎪⎪⎪⎪⎪⎭⎪
}
2
( )P X α
χ α< =
degrés de liberté: n
D’après la table de la loi de khi-deux, on a χ2
0,8 = 5, 989 ⇒ 80% des valeurs de X sont inférieures à 5, 989.
1.5 Approximation de la loi de khi-deux par la loi normale
Soit X une variable aléatoire qui suit la loi de khi-deux à n degrés de liberté (X Ã χ2
(n)). Lorsque n ≥ 30, on
admettra que la quantité
√
2X −
√
2n − 1 Ã N(0, 1).
Exemple : Déterminer le quantile d’ordre α = 0, 975 d’une khi-deux à 60 degrés de liberté.
On a X Ã χ2
(60) ⇒ Z =
√
2X −
p
2 (60) − 1 Ã N(0, 1)
⇒ 0, 975 = P (Z < Z0,975) = P
³√
2X −
√
119 < Z0,975
´
= P
µ
X <
[Z0,975+
√
119]2
2
¶
⇒ χ2
0,975(60) =
£
Z0,975 +
√
119
¤2
2
=
£
1, 96 +
√
119
¤2
2
' 83 (la valeur exacte de χ2
0,975(60) = 83, 298. Table 6)
1.6 Stabilité de la loi de khi-deux
Si X1 et X2 sont deux variables aléatoires indépendantes telles que X1 Ã χ2
(n1) et X2 Ã χ2
(n2), alors la
variable aléatoire Y définie par Y = X1 + X2 Ã χ2
(n1 + n2).
MY (t) = E
¡
etY
¢
= E
¡
et(X1+X2)
¢
= E
¡
etX1
¢
E
¡
etX2
¢
= MX1 (t) MX2 (t) =
∙
1
1 − 2t
¸n1/2
×
∙
1
1 − 2t
¸n2/2
=
∙
1
1 − 2t
¸n1+n2/2
31](https://image.slidesharecdn.com/cours-stat2-kharrat-161102173803/85/Cours-stat2-kharrat-52-320.jpg)











![4.1.2 Convergence d’un estimateur
Définition : Un estimateur ˆΘ de θ est dit convergent, s’il converge en probabilité vers θ (ˆΘ
P
−→ θ), c.-à-d :
∀ε > 0 lim
n→+∞
P
³¯
¯
¯ˆΘ − θ
¯
¯
¯ > ε
´
= 0
lim
n→+∞
P
³¯
¯
¯ˆΘ − θ
¯
¯
¯ ≤ ε
´
= 1
N.B : Une condition suffisante pour que ˆΘ converge en probabilité vers θ est que :
lim
n→+∞
E
³
ˆΘ
´
= θ et lim
n→+∞
V
³
ˆΘ
´
= 0
Exemple :
Soit (X1, X2, . . . , Xn) un EAS iid de taille n, issu d’une population X de moyenne m et de variance σ2
inconnues :
1. La moyenne empirique X est un estimateur convergent de m :
E(X) = m et lim
n→+∞
V
¡
X
¢
= lim
n→+∞
σ2
n
= 0
2. Lorsque la population est normale : la variance empirique S
0
2
et la variance empirique corrigée S2
sont deux
estimateurs convergents de σ2
:
a/ E(S02
) =
σ2
(n − 1)
n
et V (S02
) =
2 (n − 1) σ4
n2
⇒ lim
n→+∞
E(S02
) = σ2
et lim
n→+∞
V
¡
S02
¢
= 0.
b/ E
¡
S2
¢
= σ2
et V
¡
S2
¢
=
2σ4
n − 1
⇒ lim
n→+∞
V
¡
S2
¢
= 0.
L’intérêt de disposer d’un estimateur ˆΘ convergent est que, dès lors qu’on travaille sur des grands échantillons,
la probabilité pour qu’une réalisation de ˆΘ diffère sensiblement de la vraie valeur de θ est faible.
4.1.3 Comparaison d’estimateurs
Le staticien est souvent confronté au problème de choisir entre plusieurs estimateurs potentiels d’un même
paramètre. La démarche utilisée pour comparer deux (ou plusieurs) estimateurs consiste à raisonner sur ce qu’on
appelle l’écart quadratique moyen : indicateur utilisé pour mesurer la précision d’un estimateur.
Définition 1 : Soit ˆΘ un estimateur de θ. On appelle écart quadratique moyen (EQM ) de ˆΘ le réel défini par :
EQM
³
ˆΘ
´
= E
³
ˆΘ − θ
´2
De deux estimateurs ˆΘ1 et ˆΘ2 de θ, on utilisera préférentiellement celui dont l’écart quadratique moyen est le
plus faible.
Propriété de L’écart quadratique moyen
EQM
³
ˆΘ
´
= E
³
ˆΘ − θ
´2
= V
³
ˆΘ
´
+
h
B
³
ˆΘ
´i2
En effet : EQM
³
ˆΘ
´
= E
³
ˆΘ − θ
´2
= E
h
ˆΘ − E
³
ˆΘ
´
+ E
³
ˆΘ
´
− θ
i2
= E
h³
ˆΘ − E
³
ˆΘ
´´
+
³
E
³
ˆΘ
´
− θ
´i2
= E
∙³
ˆΘ − E
³
ˆΘ
´´2
+ 2
³
ˆΘ − E
³
ˆΘ
´´ ³
E
³
ˆΘ
´
− θ
´
+
³
E
³
ˆΘ
´
− θ
´2
¸
= E
³
ˆΘ − E
³
ˆΘ
´´2
| {z }
V ( ˆΘ)
+ 2
³
E
³
ˆΘ
´
− θ
´
E
³
ˆΘ − E
³
ˆΘ
´´
| {z }
0
+
³
E
³
ˆΘ
´
− θ
´2
| {z }
[B( ˆΘ)]2
= V
³
ˆΘ
´
+
h
B
³
ˆΘ
´i2
42](https://image.slidesharecdn.com/cours-stat2-kharrat-161102173803/85/Cours-stat2-kharrat-64-320.jpg)

![⇒
∂2
Logf(x, λ)
∂λ2 =
∂
³
−1 +
x
λ
´
∂λ
= −
x
λ2
⇒ I1 (λ) = −E
∙
∂2
Logf(X, λ)
∂λ2
¸
= −E
µ
−
X
λ2
¶
=
1
λ2 E(X) =
λ
λ2 =
1
λ
⇒ In (λ) = nI1 (λ) =
n
λ
2`eme
méthode :
In (λ) = −E
∙
∂2
LogL(X1, X2, . . . , Xn, λ)
∂λ2
¸
avec LogL(x1, x2, . . . , xn, λ) = Log
∙ nQ
i=1
f(xi, λ)
¸
=
nP
i=1
Log (f(xi, λ)) =
nP
i=1
Log
µ
e−λ λxi
(xi)!
¶
=
nP
i=1
(−λ + xiLogλ − Log [(xi)!])
= −nλ + Logλ
nP
i=1
xi −
nP
i=1
Log [(xi)!]
⇒
∂LogL(x1, x2, . . . , xn, λ)
∂λ
= −n +
Pn
i=1 xi
λ
⇒
∂2
LogL(x1, x2, . . . , xn, λ)
∂λ2 = −
Pn
i=1 xi
λ2
⇒ In (λ) = −E
∙
∂2
LogL(X1, X2, . . . , Xn, λ)
∂λ2
¸
= −E
µ
−
Pn
i=1 Xi
λ2
¶
=
1
λ2
Pn
i=1 E(Xi) =
nλ
λ2 =
n
λ
4.1.5 Efficacité absolue
Théorème de F.D.C.R :
Si X(Ω) est indépendant du paramètre à estimer θ, alors pour tout estimateur ˆΘ sans biais de θ on a :
V
³
ˆΘ
´
≥
1
In (θ)
Cette inégalité est généralement appelée l’inégalité de Cramer-Rao.
La quantité
1
In (θ)
est la borne inférieure de F.D.C.R.
Définition :
Un estimateur sans biais ˆΘ est dit efficace si sa variance est égale à la borne inférieure de F.D.C.R. :
V
³
ˆΘ
´
=
1
In (θ)
4.2 Les méthodes d’estimation ponctuelle
Il existe plusieurs procédés permettant de construire concrètement des estimateurs. Les méthodes d’estimation
ponctuelle les plus courantes sont :
— La méthode du maximum de vraisemblance (MV).
— La méthode des moments (MM).
— La méthode des moindres carrées ordinaires (MCO).
Nous exposerons uniquement les deux premières.
4.2.1 L’estimation par la méthode du maximum de vraisemblance
Soit (X1, X2, . . . , Xn) un EAS iid de taille n, issu d’une population X de densité de probabilité f(X, θ), θ
étant le paramètre inconnu qu’on cherche à estimer. La méthode du maximum de vraisemblance (MV) consiste
à estimer θ en choisissant la valeur ˆθ qui maximise la fonction de vraisemblance du paramètre θ sur l’échantillon
(X1, X2, . . . , Xn). Cette méthode se résume par les quatre étapes suivantes :
1. Expliciter la fonction de vraisemblance du paramètre θ estimer définie par :
L(x1, x2, . . . , xn, θ) =
nQ
i=1
f(xi, θ)
44](https://image.slidesharecdn.com/cours-stat2-kharrat-161102173803/85/Cours-stat2-kharrat-66-320.jpg)
![2. Appliquer la transformation logarithmique à la fonction de vraisemblance :
LogL(x1, x2, . . . , xn, θ) = Log
∙ nQ
i=1
f(xi, θ)
¸
=
nP
i=1
Log (f(xi, θ))
3. Appliquer la dérivée par rapport au paramètre à estimer à la fonction Log-vraisemblance et résoudre l’équation
d’inconnue θ :
∂LogL(x1, x2, . . . , xn, θ)
∂θ
= 0 ⇒ θ = ˆθ
4. Vérifier la condition :
∂2
LogL(x1, x2, . . . , xn, θ)
∂θ2
¯
¯
¯
¯
θ=ˆθ
< 0
Si cette dernière est satisfaite, alors l’estimateur du MV est celui fourni à l’étape 3
³
ˆθMV = ˆθ
´
.
Exemples :
1. Estimation du paramètre λ d’une loi de Poisson P(λ)
Soit (X1, X2, . . . , Xn) un EAS iid de taille n, issu d’une population de Poisson de paramètre λ inconnu.
Estimer le paramètre λ par la méthode du maximum de vraisemblance.
1`ere
étape : L(x1, x2, . . . , xn, λ) =
nQ
i=1
f(xi, λ) =
nQ
i=1
∙
e−λ λxi
(xi)!
¸
.
2`eme
étape : LogL(x1, x2, . . . , xn, λ) =
nP
i=1
Log
µ
e−λ λxi
(xi)!
¶
= −nλ + Logλ
nP
i=1
xi −
nP
i=1
Log [(xi)!]
3`eme
étape :
∂LogL(x1, x2, . . . , xn, λ)
∂λ
= −n +
Pn
i=1 xi
λ
= 0 ⇒ ˆλ =
1
n
Pn
i=1 xi = x.
4`eme
étape :
∂2
LogL(x1, x2, . . . , xn, λ)
∂λ2
¯
¯
¯
¯
λ=ˆλ
= −
Pn
i=1 xi
ˆλ
2 = −
nx
x2 = −
n2
Pn
i=1 xi
< 0 ⇒ ˆλMV = X .
2. Estimation des paramètres m et σ2
d’une loi normale
Soit (X1, X2, . . . , Xn) un EAS iid de taille n, issu d’une population normale de paramètres m et σ2
inconnus.
Déterminer les estimateurs du MV de m et σ2
.
On a X Ã N
¡
m, σ2
¢
⇒ ∀x ∈ R, f(x, m, σ2
) =
1
σ
√
2Π
e
−
1
2
x − m
σ
2
(X1, X2, . . . , Xn) un EAS iid ⇒
⎧
⎪⎨
⎪⎩
Les Xi sont indépendantes
Xi à N
¡
m, σ2
¢
, ∀i : 1 . . . n ⇒ f(xi, m, σ2
) =
1
σ
√
2Π
e
−
1
2
xi − m
σ
2
1`ere
étape : L(x1, x2, . . . , xn, m, σ2
) =
nQ
i=1
f(xi, m, σ2
) =
nQ
i=1
⎡
⎢
⎣
1
σ
√
2Π
e
−
1
2
xi − m
σ
2
⎤
⎥
⎦
2`eme
étape : LogL(x1, x2, . . . , xn, m, σ2
) =
nP
i=1
Log
⎛
⎜
⎝
1
σ
√
2Π
e
−
1
2
xi − m
σ
2
⎞
⎟
⎠
= −nLogσ − nLog
√
2Π −
1
2σ2
nP
i=1
(xi − m)
2
3`eme
étape :
∂LogL(x1, x2, . . . , xn, m, σ2
)
∂m
=
1
σ2
nP
i=1
(xi − m) = 0 ⇒ ˆm =
1
n
Pn
i=1 xi = x.
∂LogL(x1, x2, . . . , xn, m, σ2
)
∂σ2
= −
n
2
1
σ2
+
1
2σ4
nP
i=1
(xi − ˆm)2
= 0 ⇒ ˆσ2
=
1
n
nP
i=1
(xi − ˆm)2
⇒ ˆσ2
=
1
n
nP
i=1
(xi − x)
2
⇒ ˆσ2
= s02
4`eme
étape : X et S02
seront les estimateurs du MV de m et σ2
si la forme quadratique associée à la ma-
trice hessienne des dérivées secondes est définie négatives (conditions du second ordre pour l’existence d’un
maximum).
45](https://image.slidesharecdn.com/cours-stat2-kharrat-161102173803/85/Cours-stat2-kharrat-67-320.jpg)

![5 L’estimation par intervalle de confiance
Les expérimentateurs préfèrent donner, au lieu d’une estimation ponctuelle ˆθ du paramètre inconnu θ, un
intervalle dans lequel ils ont la quasi-certitude de cerner la vraie valeur de θ. Cet intervalle est appelé intervalle de
confiance de θ.
La quasi-certitude, dont dépend la largeur de l’intervalle, est mesurée par une probabilité appelée niveau de
confiance ou coefficient de sécurité. On ne donnera jamais un intervalle de confiance sans l’accompagner du niveau
de confiance choisi.
5.1 Définition
Un intervalle de confiance pour le paramètre θ inconnu, de niveau de confiance (1 − α) ∈ ]0, 1[, est un intervalle
qui a la probabilité 1 − α de contenir la vraie valeur du paramètre θ :
IC(1−α) (θ) = [L1, L2] ⇔ P (L1 ≤ θ ≤ L2) = 1 − α
5.2 Principe de construction de l’intervalle de confiance
La construction d’un intervalle de confiance pour un paramètre inconnu θ comporte 5 étapes :
1. Choisir un niveau de confiance 1 − α (α : seuil de signification ou risque).
2. Déterminer la distribution d’échantillonnage de la statistique à utiliser : T = f
³
ˆΘ, θ
´
à L.(f est dite fonction
pivotale). L’expression de T ne doit contenir qu’un seul inconnu : le paramètre θ
3. Présenter l’équation qui permet de déterminer l’intervalle de confiance :
P
³
k1 ≤ f
³
ˆΘ, θ
´
≤ k2
´
= 1 − α
4. Déterminer les 2 quantiles k1 et k2 à partir de la table statistique qui correspond à la loi de probabilité de
T = f
³
ˆΘ, θ
´
. k1 et k2 doivent vérifier :
P
³
f
³
ˆΘ, θ
´
< k1
´
= P
³
f
³
ˆΘ, θ
´
> k2
´
=
α
2
5. Résoudre l’inéquation k1 ≤ f
³
ˆΘ, θ
´
≤ k2 afin de déterminer l’intervalle de confiance du paramètre inconnu
θ, satisfaisant la relation suivante :
P
³
g1
³
ˆΘ
´
≤ θ ≤ g2
³
ˆΘ
´´
= 1 − α
et on a finalement : IC(1−α) (θ) =
h
L1 = g1
³
ˆΘ
´
, L2 = g2
³
ˆΘ
´i
5.2.1 Intervalle de confiance pour la moyenne
Soit (X1, X2, . . . , Xn) un EAS iid de taille n, issu d’une population X de moyenne inconnue m et de variance
σ2
.
a/ Cas où σ2
est connue : (X Ã N
¡
m, σ2
¢
et nqcq ) ou (X Ã Lqcq
¡
m, σ2
¢
et n ≥ 30)
1. Soit 1 − α le niveau de confiance choisi.
2. On sait que dans les deux cas où :
X Ã N
¡
m, σ2
¢
et nqcq
X Ã Lqcq
¡
m, σ2
¢
et n ≥ 30
¾
on a X Ã N(m,
σ2
n
) ⇒
X − m
σ/
√
n
à N(0, 1)
Ainsi, pour déterminer un intervalle de confiance pour la moyenne dans le cas où σ2
est connue, on retient la
statistique T = f
³
ˆΘ, θ
´
= f
¡
X, m
¢
=
X − m
σ/
√
n
à N(0, 1).
3. L’équation qui permet de déterminer IC(1−α) (m) est donc : P
µ
k1 ≤
X − m
σ/
√
n
≤ k2
¶
= 1 − α.
47](https://image.slidesharecdn.com/cours-stat2-kharrat-161102173803/85/Cours-stat2-kharrat-69-320.jpg)












































































