Télécharger en tant que PDF, PPTX














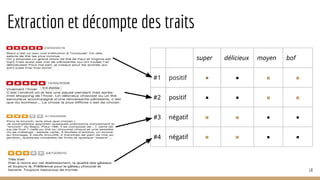












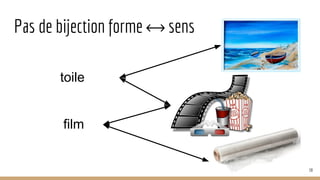



![Des unités continues
mesure, nom fém.
● action de mesurer : la mesure du temps
● quantité servant à mesurer : le mètre est une
mesure de surface
● récipient servant à mesurer : une mesure en
étain
● [MUSIQUE] division d’un morceau en parties
égales
● [POÉSIE] quantité de syllabe dans un vers
● modération : agir avec mesure
● moyen : mettre en œuvre une mesure
42
monosémie
homonymie
polysémie](https://image.slidesharecdn.com/tds-tal-160129162622/85/Decouverte-du-Traitement-Automatique-des-Langues-42-320.jpg)
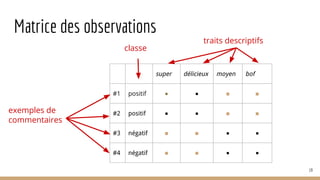
![Instabilité
● temps
○ selfie, zadiste, souris
● contexte
○ quoi vs koi
○ maman vs mère
● géographique
○ abreuvoir (CA) vs fontaine (FR)
○ chocolatine vs pain au chocolat
● domaine
○ licorne [économie] vs licorne [général]
○ extrêmités digitales [médecine] vs le bout des doigts [général]
○ assimilation [sociologie] vs assimilation [médecine] vs assimilation [linguistique]
43](https://image.slidesharecdn.com/tds-tal-160129162622/85/Decouverte-du-Traitement-Automatique-des-Langues-43-320.jpg)
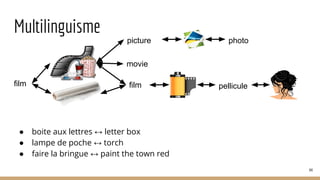



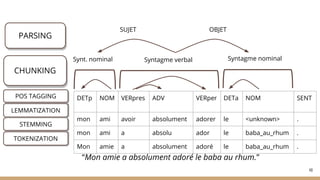




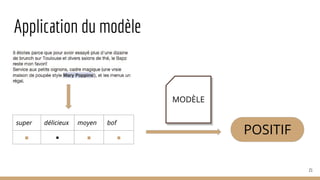
![Chunking : groupes syntaxiques
● Unités correctement délimitées
○ [J’] [ai demandé] [un verre de vin] [au serveur].
● Traits plus pertinents et précis
○ tarte : tarte aux pommes vs tarte aux pommes
○ [je] [n’ai pas aimé] → pas aimer
● Attribution de descripteurs :
53
ventes d’Iphone
baisse des ventes
économie chinoise
recul des revenus](https://image.slidesharecdn.com/tds-tal-160129162622/85/Decouverte-du-Traitement-Automatique-des-Langues-53-320.jpg)
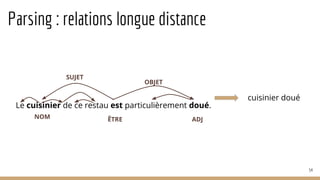
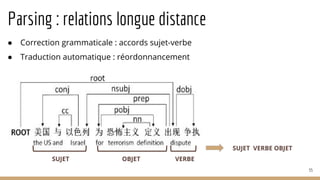











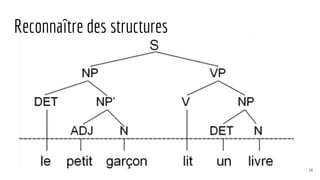
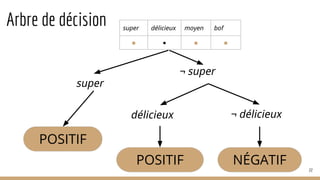
![Reconnaissance de patrons
70
Spécialiste J2EE et passionnée par mon métier, je possède 10 années d’expérience au sein de…
spécialiste de? [NP] [NB] an|années d’expérience
Domaine = J2EE Expérience = 10 ans
le petit chat dort dans son panier .
DET ADJ NOM VB PREP DET NOM SENT
[DET ADV ? ADJ ? NOM] VB|SENT [DET ADV ? ADJ ? NOM] VB|SENT
GN= le petit chat GN= son panier](https://image.slidesharecdn.com/tds-tal-160129162622/85/Decouverte-du-Traitement-Automatique-des-Langues-70-320.jpg)









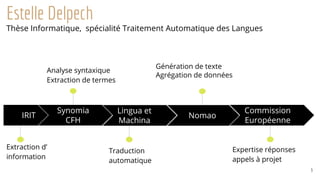
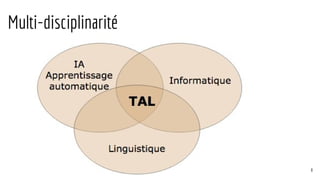
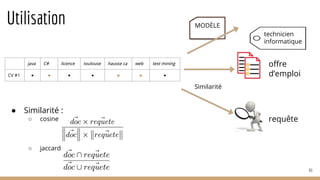
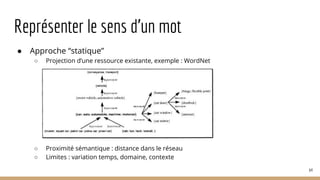
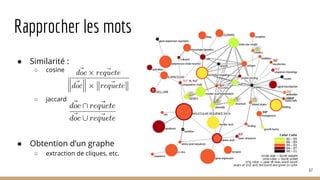
La présentation a pour but d'introduire le traitement automatique des langues (TAL) et ses enjeux, ainsi que les techniques essentielles et les ressources associées. Elle aborde des applications telles que la traduction automatique et l'analyse de sentiments, tout en soulignant l'importance de l'apprentissage automatique dans ce domaine. Les concepts clés incluent la linguistique, l'analyse syntaxique, et la représentation sémantique des documents.




































































