Téléchargé 38 fois


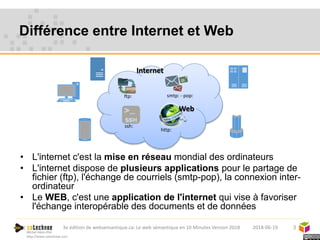


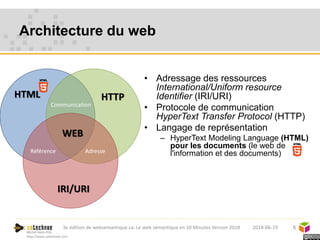
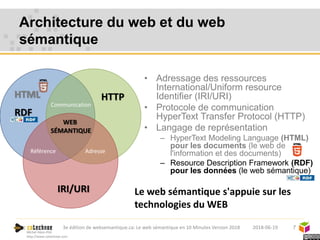
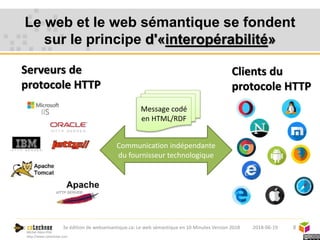



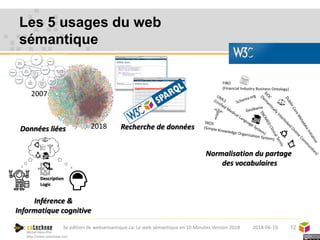
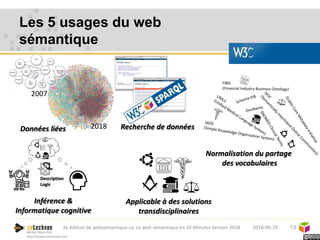

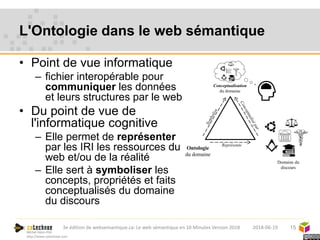

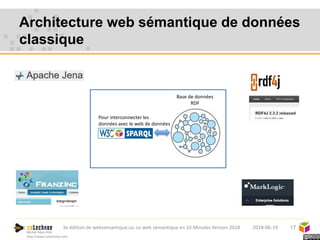

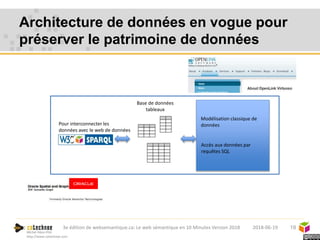
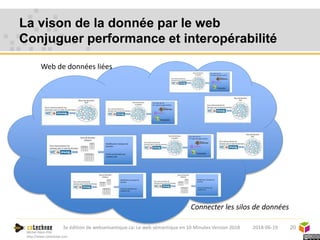



Le web sémantique, introduit par Tim Berners-Lee, vise à faciliter l'échange de documents et de données entre humains et machines en utilisant des standards ouverts. Il repose sur des technologies telles que RDF et SPARQL pour interagir avec les données, permettant une interopérabilité et une normalisation des vocabulaires. Les principales applications du web sémantique incluent les données liées, la recherche de données et le développement d'agents cognitifs.























































