


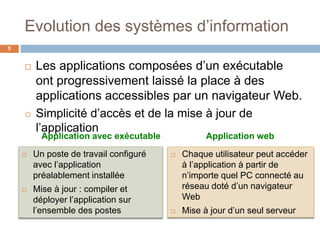








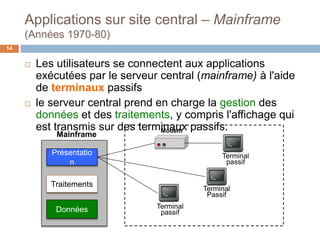


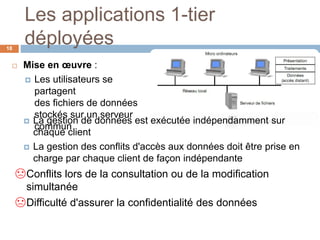



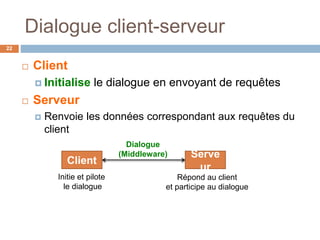


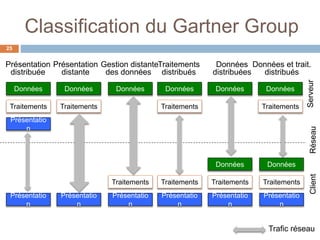



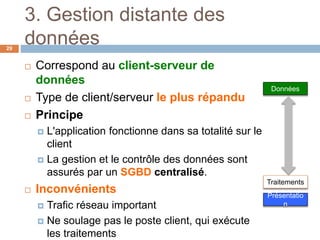












Le document présente les systèmes d'information, expliquant leur composition, l'évolution vers des applications web et la découpe en trois niveaux d'abstraction : présentation, logique applicative, et données. Il aborde les différentes architectures de systèmes d'information, notamment client/serveur et les modèles de middleware, ainsi que les architectures 1-tier et 2-tiers. Enfin, le texte discute des défis et des avantages associés à ces architectures, soulignant l'importance de la gestion centralisée des données et de l'interaction entre clients et serveurs.





































































