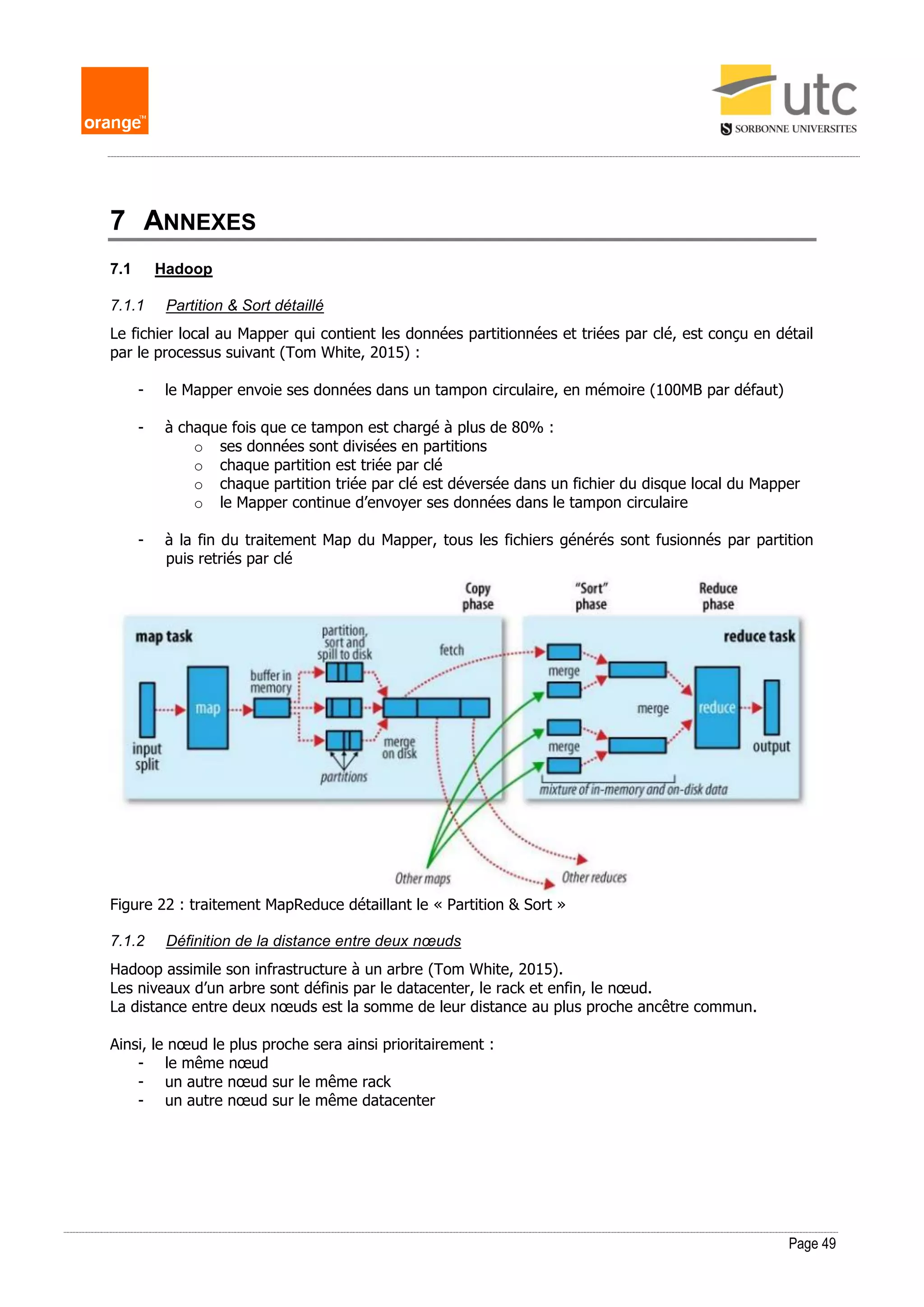
Le document examine l'utilisation de Hadoop et Hive pour le traitement des données massives dans le contexte de l'entreprise Orange, en mettant en avant les différences fondamentales entre les bases de données traditionnelles et les systèmes de big data. Il propose des stratégies d'optimisation des requêtes SQL sur Hadoop, soulignant l'importance d'une compréhension approfondie des données traitées et des compétences similaires à celles requises pour un administrateur de bases de données. Enfin, il aborde l'évolution future potentielle de ces technologies dans la gestion des données à grande échelle.













![Page 13
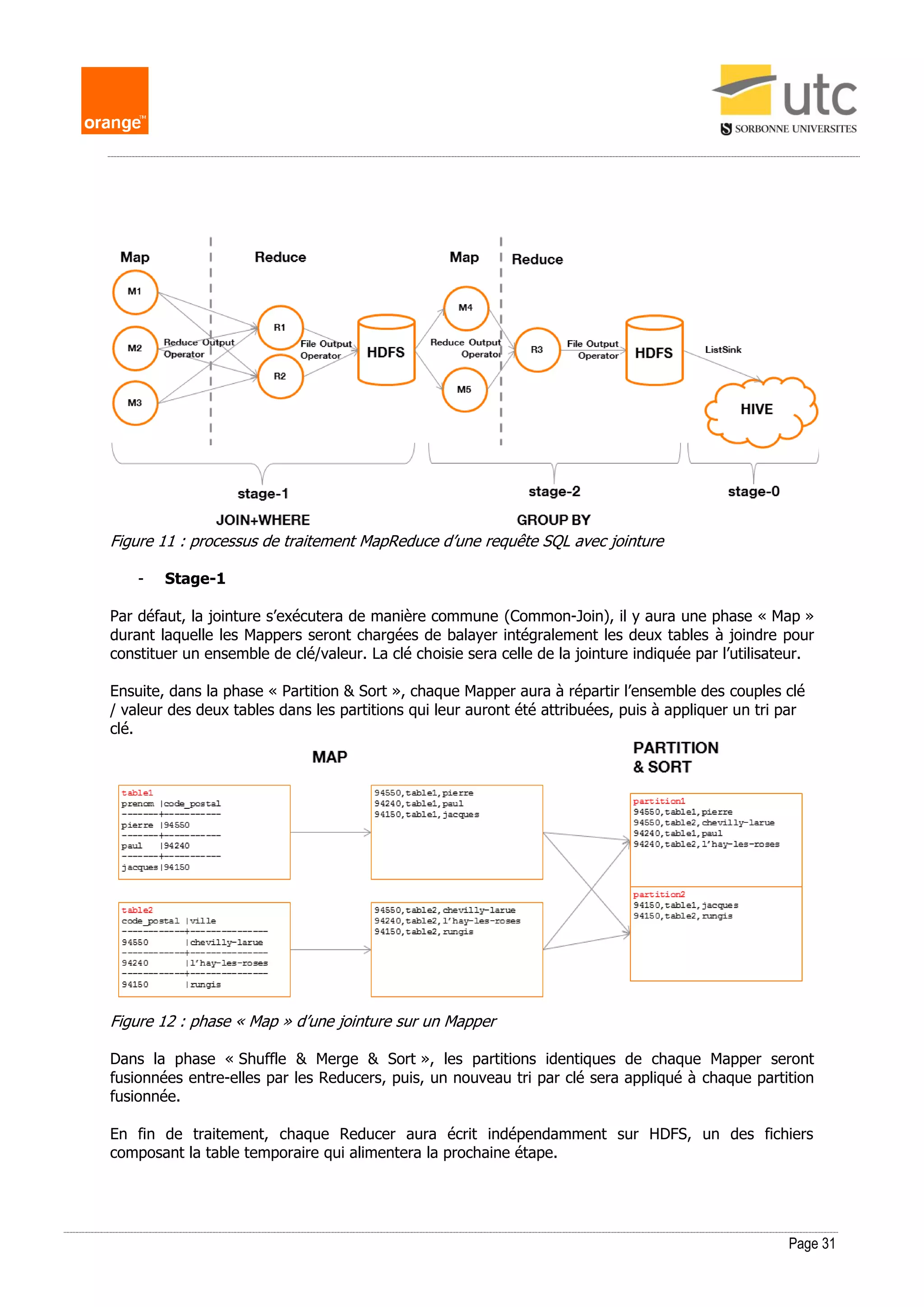
Figure 3 : répartition de trois fichiers dans un cluster HDFS
Explication :
Chaque fichier « fichierCouleurs » occupe 1 bloc de données dupliqué 3 trois fois sur un cluster de 4
DataNodes (DN) gérés par le NameNode (NN).
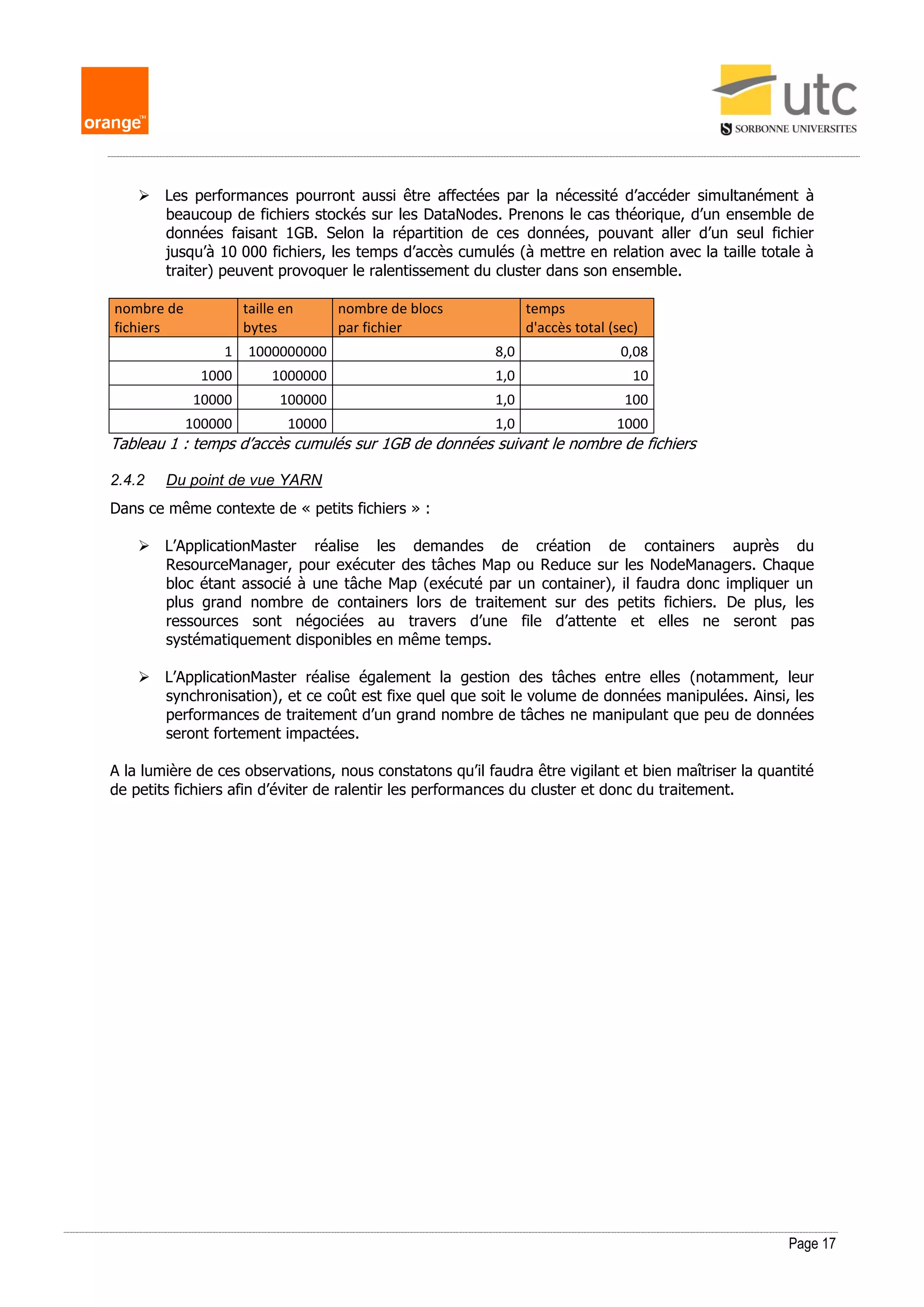
Le programme « WordCount » suivant implémente MapReduce :
public class WordCount {
public static class Map extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
context.write(word, one);
}
}
}
public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf, "wordcount");
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);](https://image.slidesharecdn.com/frackowiak-memoire-m2idl-180529192313/75/Strategies-d-optimisation-de-requetes-SQL-dans-un-ecosysteme-Hadoop-14-2048.jpg)
![Page 14
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setNumReduceTasks(2);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}
Ce programme s’exécutera dans l’architecture Hadoop et sollicitera ses différents composants :
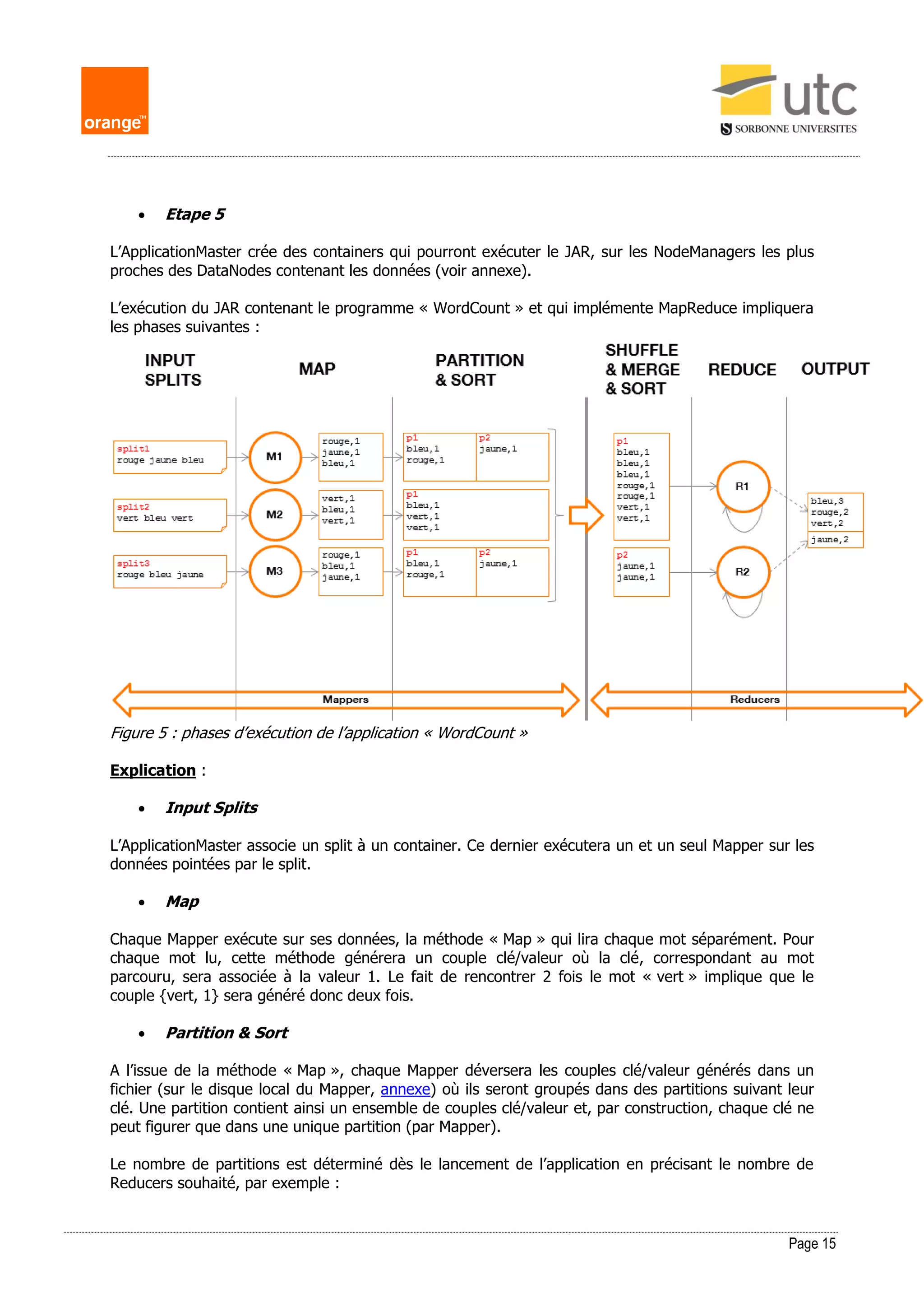
Figure 4 : phases de création des containers YARN pour l’exécution de l’application « WordCount »
Explication :
Etape 1
L’application « WordCount » sollicite le ResourceManager afin de déclarer une nouvelle application
YARN.
Etape 2
L’application « Wordcount » sollicite le NameNode afin d’obtenir la liste des blocs composant le ou les
fichiers à traiter puis dépose les références vers ces blocs (split) dans un répertoire partagé, où sera
également copié le JAR à exécuter.
Etape 3
Le ResourceManager crée un ApplicationMaster.
Etape 4
L’ApplicationMaster lit les « input splits » afin de déterminer l’emplacement des données.](https://image.slidesharecdn.com/frackowiak-memoire-m2idl-180529192313/75/Strategies-d-optimisation-de-requetes-SQL-dans-un-ecosysteme-Hadoop-15-2048.jpg)






![Page 24
Statistics:
...
Stats Publishing Key Prefix:
hdfs://NAMENODE/tmp/hive/u_xxxx_yyy/.../-ext-10001/
table:
input format:
org.apache.hadoop.mapred.TextInputFormat
output format:
org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
...
TotalFiles: 1
GatherStats: false
MultiFileSpray: false
Path -> Alias:
hdfs://NAMENODE/.../z_database1.db/table1 [table1]
Path -> Partition:
hdfs://NAMENODE/.../z_database1.db/table1
Partition
base file name: table1
input format:
org.apache.hadoop.hive.ql.io.orc.OrcInputFormat
output format:
org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat
properties:
...
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
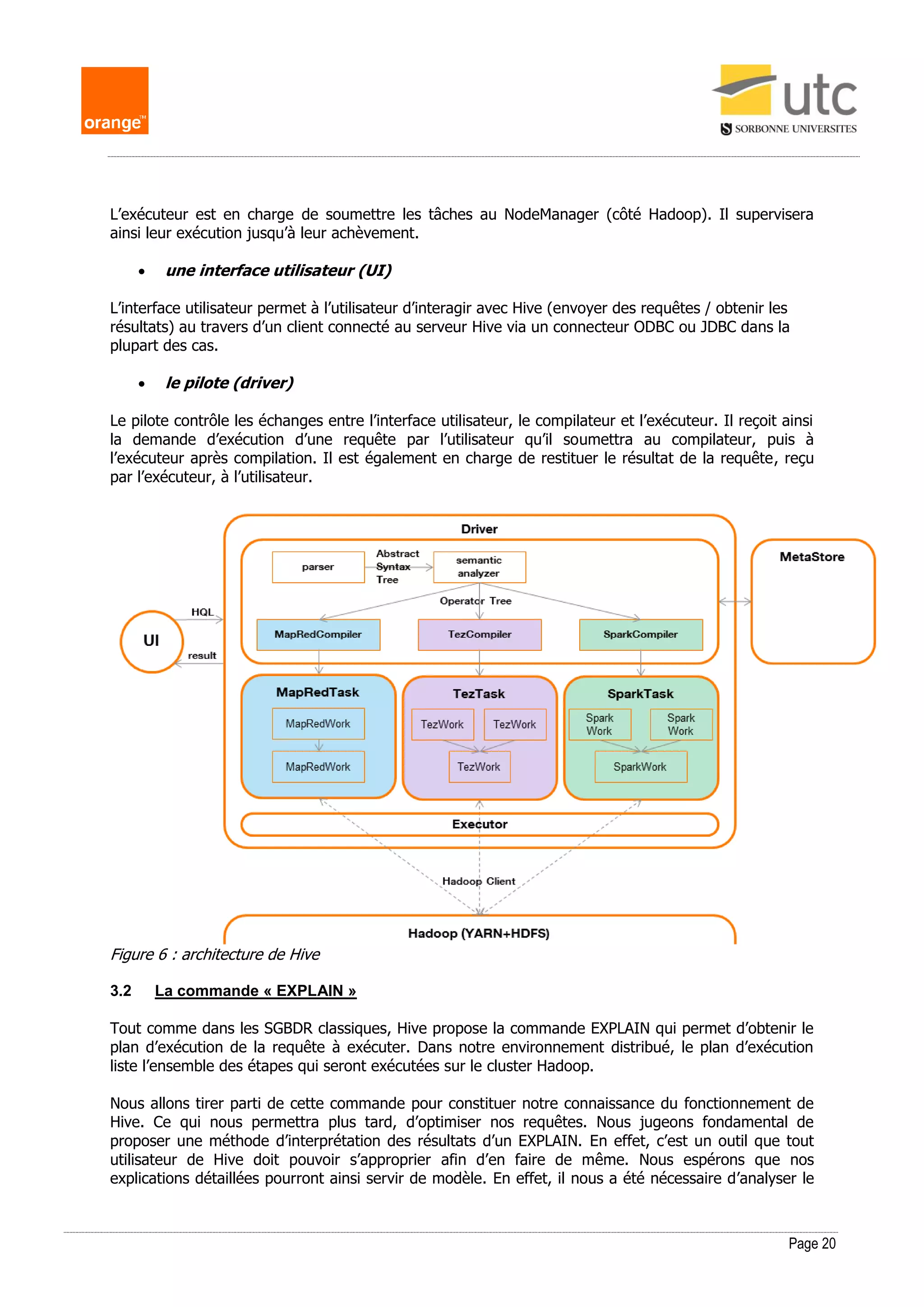
Explications :
Le résultat de cet « EXPLAIN EXTENDED » contient les 3 mêmes parties.
(1) L’arbre syntaxique abstrait
Nous remarquons qu’il contient un nouveau token « TOK_WHERE » définissant notre restriction, nous
avons en effet à présent :
- TOK_QUERY : la racine de l’arbre
o TOK_FROM : la base et la table interrogées
o TOK_INSERT : la destination du résultat dans un fichier temporaire
o TOK_SELECT : les champs sélectionnés
o TOK_WHERE : la restriction opérée sur un champ
(2) Les dépendances entre étapes
Dans notre exemple, le plan de dépendance est devenu plus complexe puisqu’il figure à présent deux
étapes :
- Stage-1 : l’étape racine
- Stage-0 : une étape dépendant de l’étape racine
(3) Le plan d’étapes
Dans notre exemple :
- Stage-0 :
o est de type « Map Reduce »](https://image.slidesharecdn.com/frackowiak-memoire-m2idl-180529192313/75/Strategies-d-optimisation-de-requetes-SQL-dans-un-ecosysteme-Hadoop-25-2048.jpg)


![Page 27
immédiatement suite au « SELECT ». L’usage habituel est d’ajouter ensuite des fonctions d’agrégation
comme « COUNT », qui s’appliqueront à chacune des partitions listées. Notre exemple n’utilise pas de
telles fonctions, pour ne pas ajouter de complexité inutile.
Le résultat de cet « EXPLAIN EXTENDED » est :
ABSTRACT SYNTAX TREE:
...
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: table1
filterExpr: (field1 = '123') (type: boolean)
Statistics:
...
GatherStats: false
Filter Operator
isSamplingPred: false
predicate: (field1 = '123') (type: boolean)
Statistics:
...
Reduce Output Operator
key expressions: field1 (type: varchar(10))
sort order: +
Map-reduce partition columns: field1 (type: varchar(10))
Statistics:
...
tag: -1
auto parallelism: false
Path -> Alias:
hdfs://NAMENODE/.../z_database1/table1 [table1]
Path -> Partition:
hdfs://NAMENODE/.../z_database1/table1
Partition
...
Reduce Operator Tree:
Group By Operator
keys: KEY._col0 (type: varchar(10))
mode: complete
outputColumnNames: _col0
Statistics:
...
File Output Operator
...
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
Nous ne reviendrons ni sur l’arbre syntaxique abstrait (qui ajoute à l’exemple précédent un nouveau
token « TOK_GROUPBY ») ni sur les dépendances entre étapes (qui sont strictement identiques à
l’exemple précédent : Stage-1 Stage-0).
Détaillons en revanche le plan d’étapes :](https://image.slidesharecdn.com/frackowiak-memoire-m2idl-180529192313/75/Strategies-d-optimisation-de-requetes-SQL-dans-un-ecosysteme-Hadoop-28-2048.jpg)




















![Page 51
--------------------------------------------------------------------------------
VERTICES: 00/03 [>>--------------------------] 0% ELAPSED TIME: xx.xx s
--------------------------------------------------------------------------------](https://image.slidesharecdn.com/frackowiak-memoire-m2idl-180529192313/75/Strategies-d-optimisation-de-requetes-SQL-dans-un-ecosysteme-Hadoop-52-2048.jpg)






















































