Téléchargé 75 fois










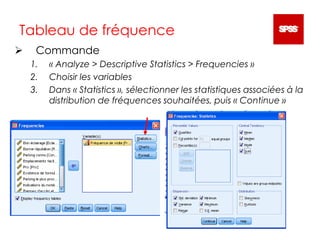










































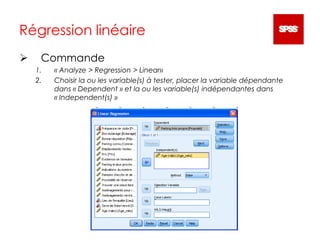









Ce document sert d'introduction à l'utilisation du logiciel PASW Statistics 18 pour l'analyse de données. Il couvre les manipulations de base, différentes analyses statistiques telles que l'analyse descriptive, les tests de moyenne, le chi-carré, l'ANOVA, la régression linéaire et la corrélation. Des instructions détaillées sur l'utilisation des commandes dans le logiciel sont fournies pour réaliser des études sur des variables qualitatives et quantitatives.















![Ch4 andoneco [mode de compatibilité]](https://cdn.slidesharecdn.com/ss_thumbnails/ch4andonecomodedecompatibilit-140429111854-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





























































