Téléchargé 82 fois











































![62
LE GROUPE MICROPOLE1 100 COLLABORATEURS
100 M€ de CA
25+ ANS
D'EXPERTISE OPÉRATIONNELLE
7 SITES EN FRANCE
[PARIS / LYON / AIX-EN-PROVENCE /
SOPHIA ANTIPOLIS / TOULOUSE /
RENNES / NANTES / LILLE]
5 SITES EN EUROPE
[GENÈVE / LAUSANNE / ROTTERDAM /
BRUXELLES / LUXEMBOURG]
3 SITES EN CHINE
[PÉKIN / SHANGHAÏ / HONG KONG]
UN POSITIONNEMENT
DE SPÉCIALISTE
Alliance d’expertises
fonctionnelles et techniques
Une agence intégrée spécialisée
dans l’Expérience Client (Wide)
Savoir-faire historique centré Data
Intelligence et Digitalisation des
processus Internes / Externes
UNE CULTURE DE L'INNOVATION
Au cœur de notre expertise, tournée
vers les usages au service de nos clients
Accompagnement de « Start Up »
valorisant la donnée
Diffusion de l’innovation : Micropole Lab
Network](https://image.slidesharecdn.com/micropole-matinaledatascience-24012017-170125102211/85/Matinee-Decouverte-Big-Data-Data-Science-24012017-62-320.jpg)


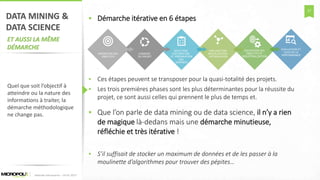
Le document explore la transformation numérique à travers le prisme du big data et de la data science, en soulignant les meilleures pratiques et l'importance de la gouvernance. Il met en évidence comment la data science, essentielle pour de nombreux projets de big data, doit s'adapter aux enjeux métiers et que la compréhension des données et de leur exploitation est cruciale. Enfin, il aborde les évolutions technologiques et leur impact sur différents secteurs, tout en posant des questions sur l'avenir de l'emploi et les impacts sociétaux du big data.















![[French] Matinale du Big Data Talend](https://cdn.slidesharecdn.com/ss_thumbnails/matinaledubigdatatalend-141008041011-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)
















![[MaddyTalk] La Ville - Carnet de tendances](https://cdn.slidesharecdn.com/ss_thumbnails/maddytalk-lavillecarnetdetendances-161013093201-thumbnail.jpg?width=640&height=640&fit=bounds)






















































