Téléchargé 95 fois




![Données non structurées
Les données non structurées sont des
données représentées ou stockées sans
format prédéfini
[1] Données non structurées textuelles
Données générées par courriels, présentations
PowerPoint, documents Word, messageries
instantanées, Réseaux sociaux,….
[2] Données non structurées non textuelles
Données générées via des supports tels que les
images JPEG, les fichiers audio MP3, ou encore les
fichiers vidéo Flash, …](https://image.slidesharecdn.com/presentationbigdata2-161124084216/85/De-la-business-intelligence-au-Big-Data-6-320.jpg)





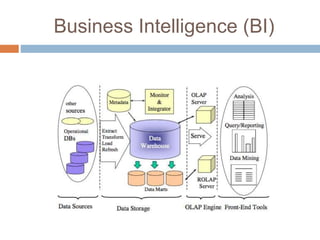
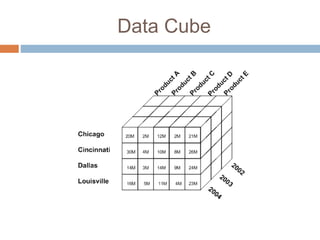
Le document présente l'évolution de la business intelligence (BI) vers le big data, en mettant en lumière que la BI aide à collecter et modéliser des données pour des analyses décisionnelles, mais est limitée dans le traitement des données non structurées. Le big data émerge comme une solution pour gérer ces données non structurées en intégrant des architectures et des technologies adaptées, permettant une analyse en temps réel. Les trois caractéristiques essentielles du big data sont le volume, la vélocité et la variété des données.























































































