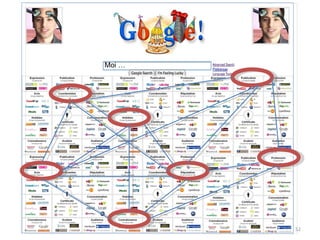
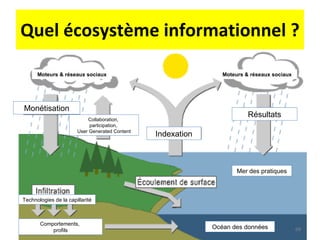
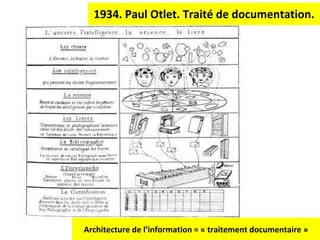
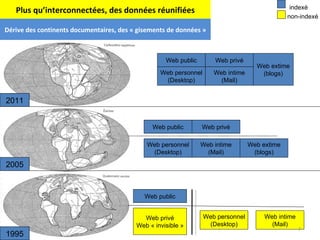
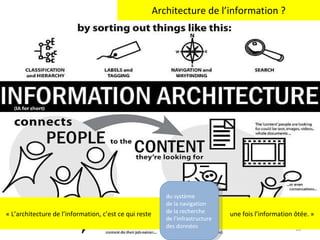
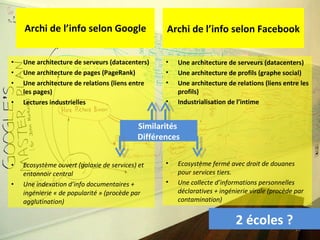
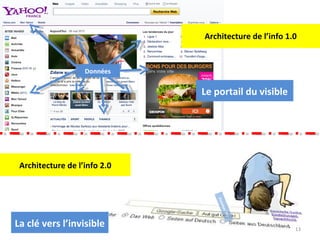
Le document aborde la gestion des données personnelles à travers l'évolution des architectures de l'information sur le web, mettant en lumière la manière dont les données personnelles sont collectées, traitées et utilisées par des moteurs et réseaux sociaux. Il soulève des questions éthiques concernant la vie privée et les implications économiques de cette collecte massive de données, ainsi que les enjeux documentaires qui en découlent. En s'appuyant sur divers exemples, il souligne la transition d'un web de documents à un web de données connectées.











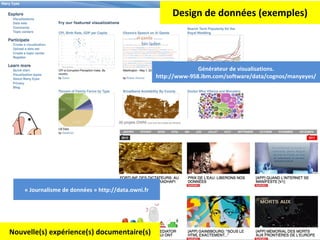


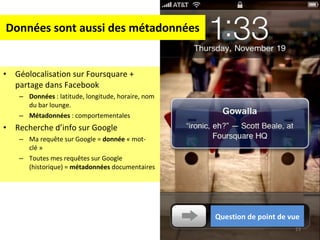













![La guerre des carnets d’adresses Mais d’abord une devinette. Bataille Google / Facebook. Enjeu : amorçage. Résultat : [email_address] Courriel = cheval de troie idéal de nos pratiques connectées. Pourquoi ? "synthétise" notre réseau relationnel (nos "contacts"), point d'entrée le plus aisé vers le cloud computing "intime", "personnel » (pub contextuelle) point pivot autour duquel hiérarchiser l'ensemble des autres données](https://image.slidesharecdn.com/ecole-ete-ertzscheid-110516040055-phpapp02/85/Gestion-des-donnees-personnelles-42-320.jpg)